BAHASA PEMROGRAMAN C
PENGANTAR PEMROGRAMAN BAHASA C
1. Pertama teman-teman buka dulu text editor nya, kalau di linux (gedit) di windows (notepad/notepad++) atau bisa juga memakai compiler yang lain yang ada pada windows seperti Dev C++ atau CodeBlock. Kalau masih bingung mengenai text editor atau compiler silahkan baca Pengenalan Bahasa C.
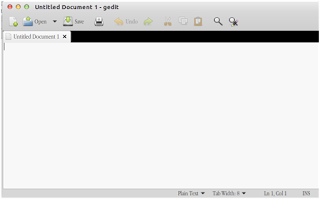
Tampilan Text Editor (Gedit) di Ubuntu
2. Setelah text editornya berhasil terbuka, teman-teman
save terdahulu file nya dengan menekan tombol CTRL+S. Setelah itu teman-teman
terserah mau simpan filenya dimana. Saya misalnya, saya simpan di Documents
dengan nama file hello.c .Ekstensi file .c itu jangan lupa untuk dibuat agar
program kita bisa berjalan dengan baik, itu adalah ekstensi program bahasa C.

Tampilan text Editor setelah di save dengan .c
3. Setelah berhasil di save, selanjutnya kita mulai dengan
menulis program nya, silahkan ketik program di bawah ini :
#include<stdio.h>
int main(){
printf(“Hello World !! \n”);
}
Catatan : “Kalau memakai Dev C++ atau Codeblock maka tinggal mengcompilenya saja dengan menekan tombol run,maka hasilnya akan muncul”
5. Karena saya memakai text Editor, maka kita mengcompile nya menggunakan terminal di ubuntu atau cmd diwindows.


ASCII merupakan kependekan dari American Standard Code for Information Interchange, sehingga dapat ditebak bahwa ASCII ini dibuat oleh Amerika, yang memang ditujukan untuk mengakomodasi karakter yang digunakan pada bahasa mereka dan oleh sebab itu ASCII generasi pertama ini sering disebut US-ASCII.
Character Set ASCII hanya terdiri dari 128 karakter yang terdiri dari karakter nyata (huruf, angka, simbol dan tanda baca) dan karakter tidak nyata (tab, enter, alt, dsb), contoh karakter ASCII adalah seperti yang ada pada tombol keyboard yang kita gunakan sekarang ini, untuk lebih lengkapnya dapat dilihat pada tabel ini.
Kenapa hanya 128 karakter? ya karena memang pada saat itu hanya karakter tersebut yang diperlukan dan sistem yang ada hanya dapat menampung sejumlah karakter terebut dan sampai dengan saat ini saya rasa masih cukup memadahi.
Setiap karakter yang ada pada ASCII cukup ditampung kedalam 7 bit binary digit, sehingga dapat dikatakan ASCII menggunakan 7 bit sistem encoding, contoh:
meskipun 7 bit, ruang penyimpanan yang dibutuhkan tetap 1 byte (8 bit),
sehingga pada skema sistem 8 bit, 7 bit pertama digunakan untuk menyimpan
karakter ASCII sedangkan bit ke delapan bernilai 0, dari sini kemudian muncul
pertanyaan bukankah 1 bit yang tersisa bisa digunakan untuk menyimpan karakter
lain?
Hal tersebut karena dengan ASCII, mereka tidak dapat menggunakan karakter yang ada pada bahasa mereka, sehingga pertukaran data tidak dapat dilakukan dengan baik.
Permasalahan tersebut menjadi isu penting dan akhirnya pada tahun 1987 direlease versi pertama dari ISO-8859-1 atau Latin1 (beberapa ada yang menggunakan istilah Extended ASCII, 8 bit ASCII atau ASCII – bukan US-ASCII) yang diadopsi dari ECMA Standard (European Computer Manufacturers Association).
Angka 1 pada ISO-8859-1 berarti standard encoding pertama dari seri ISO-8859 yang terdaftar di ISO.
Karakter yang ada pada ISO-8859-1 hanya terdiri dari karakter ASCII ditambah dengan beberapa karakter yang khusus digunakan di bahasa negara-negara Eropa Barat, penambahan ini dimulai dari karakter ke 128 s.d 255.
Kenapa 128 bukan 129? bukankah ASCII jumlah karakternya 128? ya betul, ASCII jumlah karakternya 128, namun urutan karakter dimulai dari 0, sehingga penghitungan karakter dimulai dari 0.
Karakter yang ada pada ISO-8859-1 dapat dilihat di http://www.ascii-code.com/
Karakter pada Latin1 tetap berukuran 1 byte, karena seperti disebutkan sebelumnya bahwa masih terdapat 1 bit tersisa pada sistem encoding ASCII, penggunaan 1 bit ini berdampak bertambahnya kombinasi bilangan biner sehingga dalam sistem 8 bit dapat diperoleh karakter berjumlah 256(2^8).
Penggunaan 1 byte ini disebut juga single byte encoding. Berikut ini contoh karakter Latin1 dan nilai binary nya:
Pada tabel diatas terlihat bahwa setiap karakter terdiri dari 8 binary digit
(1 byte). Untuk karakter lainnya dapat dilihat pada link berikut ini.
Munculnya Latin1 ini ternyata belum dapat mengatasi keterbatasan penggunaan karakter, seperti penggunaan karakter di negara negara Eropa Tengah dan Timur, oleh karena itu perlu dikembangkan character set lain yang dapat mengakomodasi karakter tersebut.
Mulailah bermunculanlah character set baru yang diberi nama ISO-8859-2 atau Latin2, ISO-8859-3 atau Latin3, dan seterusnya hingga ISO-8859-16 yang direlease tahun 2001. Masing masing character set spesifik untuk bahasa tertentu dan tujuan tertentu. Untuk detail seri ISO 8859 dapat dibaca di wikipedia.
Secara umum format character set ISO-8859-x adalah karakter ke 0 s.d 127 untuk karakter ASCII sedangkan sisanya karakter tambahan. contoh:
Untuk mengatasi hal tersebut, perlu dikembangkan suatu character set yang dapat menampung sekaligus banyak karakter, tidak hanya 256, jika perlu dapat menampung semua karakter yang digunakan oleh semua bahasa di dunia ini, dan yang pasti tidak mungkin bisa menggunakan sistem single byte encoding.
Dilatarbelakangi hal tersebut muncullah Unicode Character Set yang dikembangkan oleh Unicode Consortium.
Saat ini Unicode dapat mengcover lebih dari 1.100.000 karakter, angka tersebut sangat cukup untuk mengakomodasi semua karakter yang digunakan semua bahasa di dunia ini.
Dari waktu kewaktu, karakter baru terus ditambahkan, tidak hanya bahasa resmi negara tetapi juga bahasa daerah termasuk aksara jawa, Bali Bugis, Sunda, dll
Sampai dengan saat ini (Unicode Versi 8.o – di release 17 Juni 2015) jumlah karakter yang ditambahkan baru sebanyak 120.737, sehingga baru terpakai sekitar 12% dari kapasitas yang ada, masih sisa tersisa 88% yang masih sangat cukup untuk penggunaan jangka panjang.
Dengan perkembangan yang ada dapat dikatakan bahwa unicode characterset is the last character set. Waktu yang akan membuktikannya.
Sistem encoding ini sama dengan yang digunakan pada UCS-2 (2-byte Universal Character Set) – didefinisikan oleh ISO 10646, yang sudah terlebih dahulu diperkenalkan.
Pada generasi awal unicode ini belum dikenal istilah UTF-16 karena memang hanya satu sistem encoding yang digunakan.
Dengan basis 16 bit, karakter yang ditampung mencapai 65.536 karakter (216), sistem tersebut berlangsung hingga Unicode versi 1.1.0 (1991 s.d 1995).
Semakin lama sistem encoding yang ada tidak cukup menampung karakter baru yang belum ditambahkan, oleh karena itu diperkenalkanlah UTF-16 atau disebut juga Extended UCS-2 yang direlease tahun 1996.
UTF-16 merupakan sistem variable length encoding yang berarti setiap code point (kode yang mencerminkan suatu karakter) di encode menggunakan satu atau dua kali 16-bit (1 code unit = 16 bit).
Sederhananya setiap karakter unicode di encode menjadi 16 bit (1 code unit) atau 32 bit (2 code unit) tergantung jenis karakternya.
16 bit pertama digunakan untuk mengencode karakter yang ada pada Basic Multilanguage Plane BMP (karakter ke 0 s.d 65.535), sedangkan 16 bit berikutnya digunakan untuk mengencode karakter tambahan.
BPM sudah mencakup sangat banyak karakter dan simbol, mulai dari bahasa yang umum hingga yang rumit seperti CJK (China, Jepang, Korea), disamping itu juga sudah menampung aksara daerah dari berbagai negara, seperti yang ada di kita: aksara Jawa (Unicode versi 5.2), Bali, Sunda dan Batak.
Perbedaan karakter yang dapat diencode oleh UTF-16 dan UCS-2 tampak seperti pada tabel berikut:
Keuntungan penggunaan UTF-16 adalah karakter pada BMP
diencode menggunakan sistem fixed length 16bit,
sehingga mudah untuk diindex (mendukung byte order dependent), tidak seperti
pada utf8 yang menggunakan 8 s.d 24 bit.
Meski demikian, karakter yang semestinya bisa diencode menggunakan sistem 8 bit, harus diencode menggunakan sistem 16 bit, seperti pada karakter ASCII, yang artinya yang seharusnya bisa disimpan menggunakan ruang 1 byte dipaksa menggunakan 2 byte, sehingga UTF-16 ini cocok digunakan pada aplikasi yang mementingkan speed dan tidak mempermasalahkan ruang penyimpanan.
Kelemahan lain adalah sama sekali tidak mendukung karakter ASCII, karena jelas sistem encoding yang digunakan berbeda, sehingga karakter yang disimpan dengan sistem encoding ASCII tidak dapat dibuka oleh aplikasi yang menggunakan sistem encoding UTF-16.
Saat ini UTF-16 masih populer digunakan, diantaranya: bahasa pemrograman Java, C#, Objective C dan Windows API
Angka 32 pada UTF berarti 32 bit dan 4 pada UCS berarti 4 byte, yang dapat diartikan bahwa space yang digunakan untuk menyimpan suatu karakter adalah 4 byte atau 32 bit.
UTF-32 merupakan alternatif dari UTF-16, jika pada UTF-16 terdapat penggunaan sistem doubel 16 bit (untuk karakter ke 65.535 keatas), UTF-32 menggunakan fixed – width encoding, dengan base 32 bit (1 code unit = 32 bit), dimana semua karakter disimpan menggunakan sistem 32 bit encoding.
Akibatnya setiap karakter membutuhkan ruang penyimpanan sebesar 4 byte (32 bit), meskipun sebenarnya terdapat karakter yang hanya menggunakan 8 bit, sehingga pada UTF-32, yang terisi hanya 8 bit pertama, sisanya bernilai 0.
Dengan model encoding seperti ini, binary dapat diindex/diurutkan (mendukung byte order dependent) – seperti pada ASCII, sehingga pencarian suatu karakter dapat dilakukan lebih cepat.
Meski demikian encoding ini memiliki kelemahan yaitu memakan banyak space dan memory, yang tentu saja tidak efisien, contoh kata halo pada UTF-32 membutuhkan ruang penyimpanan 16 byte, sedangkan pada ASCII cukup 4 byte.
Contoh karakter dan nilai binary nya pada UTF-32:
karena semua karakter diencode pada 32 bit maka karakter yang sering
digunakan pun (karakter ke 0 s.d 65536) yang ada di BMP juga akan disimpan
sebesar 4 byte yang tentu saja lebih efisien menggunakan UTF-16 karena
hanya membutuhkan ruang penyimpanan 2 byte. Oleh karena itu penggunaan UTF-32
saat ini sudah jarang ditemui.
UTF-8 menggunakan sistem variable length encoding dengan basis 8 bit (1 code unit = 8bit), angka ini tercermin pada angka 8 yang berada di belakang UTF.
Sistem variable length berarti karakter di encoding menggunakan pola tertentu dengan panjang bit tidak tetap tergantung jenis karakternya, bisa 8, 16, 24 atau 32 bit. Pembagian penggunaan bit adalah sebagai berikut:
Pada UTF-8 sistem 1 byte encoding yang digunakan sama persis dengan sistem yang digunakan pada ASCII sehingga UTF-8 kompatibel dengan karakter ASCII, yang artinya karakter yang disimpan menggunakan sistem encoding ASCII dapat dibuka menggunakan sistem encoding UTF.
Perbandingan bit yang digunakan
Perbandingan bit yang digunakan pada ketiga sistem encoding yang ada pada Unicode Standar tampak seperti pada tabel berikut:
Pada awal munculnya ASCII standard hingga ISO-8859-x istilah character set dan sistem encoding merujuk ke standar itu sendiri, misal istilah ASCII Character Set digunakan untuk menyebut character set yang digunakan ASCII, dan ASCII encoding untuk menyebut sistem encoding pada ASCII.
Meskipun sebenarnya istilah ASCII lebih tepat digunakan untu character set, begitu juga dengan ISO-8958-1 atau Latin1 standar.
Pada awal muncul Unicode standar pun, istilah yang sama masih masih dapat digunakan, namun setelah muncul UTF-16, istilah character set dan sistem encoding mulai agak membingungkan
Banyak yang menyebut UTF sebagai character set dan Unicode adalah sistem encoding padahal sebenarnya UTF adalah sistem encoding dan Unicode lebih tepat digunakan untuk menyebut character set, walaupun Unicode sendiri hanya merupakan suatu standar.
Contoh pada dokumen HTML sering kita jumpai meta tag berikut:
<meta Content-Type: text/html; charset=utf-8>
Dalam mengartikan tag diatas, mungkin beberapa orang menganggap bahwa
Hal yang sama juga terjadi pada istilah dalam dunia database, seperti MySQL yang menyebut utf8, utf16, utf32 dan utf8mb4 sebagai character set.
Character set pertama adalah ASCII yang diperkenalkan tahun 1960, sejak itu muncul berbagai character set yang semuanya ditujukan untuk menampung karakter yang dibutuhkan namun terbatas hanya untuk regional tertentu dan tujuan tertentu.
Tahun 1991 mulai diperkenalkan Unicode Standar atau sering disebut Unicode Character Set yang dapat menampung semua karakter yang ada baik yang sudah ada pada character set lain maupun yang belum terdefinisi, dan hingga saat ini Unicode merupakan satu standar yang paling banyak digunakan terutama untuk pertukaran data di internet










1. Tipe Data Dasar
Sesuai dengan namanya, tipe data dasar adalah tipe data paling dasar yang tersedia di dalam bahasa pemrograman C. Terdapat 3 jenis tipe data dasar:
2. Tipe Data Turunan
Tipe data turunan berasal dari tipe data dasar yang dikelompokkan atau di modifikasi. Terdapat 3 tipe data turunan di dalam bahasa pemrograman C:
3. Tipe Data Bentukan (enum)
Sesuai dengan namanya, tipe data bentukan adalah tipe data yang dibuat sendiri oleh kita (programmer). Isinya berupa data-data yang sudah ditentukan. Tipe data bentukan ini dikenal juga sebagai Enumerated Data Type atau disingkat sebagai enum.
4. Tipe Data Void
Tipe data void adalah tipe data khusus yang menyatakan tidak ada data. Penggunaannya khusus untuk beberapa situasi seperti function yang tidak mengembalikan nilai (return void), atau mengisi argumen function dengan nilai kosong.
Tanpa pengelompokan, berikut ke-8 tipe data dalam bahasa pemrograman C:
Bahasa C memang tidak memiliki tipe boolean bawaan, tapi bisa diakali dengan membuatnya menggunakan tipe data bentukan (enum), atau menggunakan library khusus: stdbool.h.
Sedangkan untuk string, di dalam bahasa C termasuk ke dalam array. String di defenisikan sebagai array dari tipe data char.
Bisa juga dibilang sebagai variabel yang tidak bisa diubah nilainya.
Ada dua cara pembuatan konstanta pada C:
Pada
Pada
Posisi penulisan untuk
Oh iya, untuk nama konstanta disarankan menggunakan huruf kapital untuk menandakan itu sebuah konstanta.
Apa yang akan terjadi jika saya mencoba mengisi nilai ke dalam konstanta?
Ya programnya akan error.



Increment adalah operasi bilangan dimana bilangan hasil merupakan bilangan asal ditambah satu, sedangkan decrement adalah operasi bilangan dimana bilangan hasil merupakan bilangan asal dikurang satu.
1. Pertama teman-teman buka dulu text editor nya, kalau di linux (gedit) di windows (notepad/notepad++) atau bisa juga memakai compiler yang lain yang ada pada windows seperti Dev C++ atau CodeBlock. Kalau masih bingung mengenai text editor atau compiler silahkan baca Pengenalan Bahasa C.
Tampilan Text Editor (Gedit) di Ubuntu
2. Setelah text editornya berhasil terbuka, teman-teman
save terdahulu file nya dengan menekan tombol CTRL+S. Setelah itu teman-teman
terserah mau simpan filenya dimana. Saya misalnya, saya simpan di Documents
dengan nama file hello.c .Ekstensi file .c itu jangan lupa untuk dibuat agar
program kita bisa berjalan dengan baik, itu adalah ekstensi program bahasa C.
Tampilan text Editor setelah di save dengan .c
3. Setelah berhasil di save, selanjutnya kita mulai dengan
menulis program nya, silahkan ketik program di bawah ini :
#include<stdio.h>
int main(){
printf(“Hello World !! \n”);
}
Catatan : “Kalau memakai Dev C++ atau Codeblock maka tinggal mengcompilenya saja dengan menekan tombol run,maka hasilnya akan muncul”
5. Karena saya memakai text Editor, maka kita mengcompile nya menggunakan terminal di ubuntu atau cmd diwindows.
ASCII merupakan kependekan dari American Standard Code for Information Interchange, sehingga dapat ditebak bahwa ASCII ini dibuat oleh Amerika, yang memang ditujukan untuk mengakomodasi karakter yang digunakan pada bahasa mereka dan oleh sebab itu ASCII generasi pertama ini sering disebut US-ASCII.
Character Set ASCII hanya terdiri dari 128 karakter yang terdiri dari karakter nyata (huruf, angka, simbol dan tanda baca) dan karakter tidak nyata (tab, enter, alt, dsb), contoh karakter ASCII adalah seperti yang ada pada tombol keyboard yang kita gunakan sekarang ini, untuk lebih lengkapnya dapat dilihat pada tabel ini.
Kenapa hanya 128 karakter? ya karena memang pada saat itu hanya karakter tersebut yang diperlukan dan sistem yang ada hanya dapat menampung sejumlah karakter terebut dan sampai dengan saat ini saya rasa masih cukup memadahi.
Setiap karakter yang ada pada ASCII cukup ditampung kedalam 7 bit binary digit, sehingga dapat dikatakan ASCII menggunakan 7 bit sistem encoding, contoh:
meskipun 7 bit, ruang penyimpanan yang dibutuhkan tetap 1 byte (8 bit),
sehingga pada skema sistem 8 bit, 7 bit pertama digunakan untuk menyimpan
karakter ASCII sedangkan bit ke delapan bernilai 0, dari sini kemudian muncul
pertanyaan bukankah 1 bit yang tersisa bisa digunakan untuk menyimpan karakter
lain?
Hal tersebut karena dengan ASCII, mereka tidak dapat menggunakan karakter yang ada pada bahasa mereka, sehingga pertukaran data tidak dapat dilakukan dengan baik.
Permasalahan tersebut menjadi isu penting dan akhirnya pada tahun 1987 direlease versi pertama dari ISO-8859-1 atau Latin1 (beberapa ada yang menggunakan istilah Extended ASCII, 8 bit ASCII atau ASCII – bukan US-ASCII) yang diadopsi dari ECMA Standard (European Computer Manufacturers Association).
Angka 1 pada ISO-8859-1 berarti standard encoding pertama dari seri ISO-8859 yang terdaftar di ISO.
Karakter yang ada pada ISO-8859-1 hanya terdiri dari karakter ASCII ditambah dengan beberapa karakter yang khusus digunakan di bahasa negara-negara Eropa Barat, penambahan ini dimulai dari karakter ke 128 s.d 255.
Kenapa 128 bukan 129? bukankah ASCII jumlah karakternya 128? ya betul, ASCII jumlah karakternya 128, namun urutan karakter dimulai dari 0, sehingga penghitungan karakter dimulai dari 0.
Karakter yang ada pada ISO-8859-1 dapat dilihat di http://www.ascii-code.com/
Karakter pada Latin1 tetap berukuran 1 byte, karena seperti disebutkan sebelumnya bahwa masih terdapat 1 bit tersisa pada sistem encoding ASCII, penggunaan 1 bit ini berdampak bertambahnya kombinasi bilangan biner sehingga dalam sistem 8 bit dapat diperoleh karakter berjumlah 256(2^8).
Penggunaan 1 byte ini disebut juga single byte encoding. Berikut ini contoh karakter Latin1 dan nilai binary nya:
Pada tabel diatas terlihat bahwa setiap karakter terdiri dari 8 binary digit
(1 byte). Untuk karakter lainnya dapat dilihat pada link berikut ini.
Munculnya Latin1 ini ternyata belum dapat mengatasi keterbatasan penggunaan karakter, seperti penggunaan karakter di negara negara Eropa Tengah dan Timur, oleh karena itu perlu dikembangkan character set lain yang dapat mengakomodasi karakter tersebut.
Mulailah bermunculanlah character set baru yang diberi nama ISO-8859-2 atau Latin2, ISO-8859-3 atau Latin3, dan seterusnya hingga ISO-8859-16 yang direlease tahun 2001. Masing masing character set spesifik untuk bahasa tertentu dan tujuan tertentu. Untuk detail seri ISO 8859 dapat dibaca di wikipedia.
Secara umum format character set ISO-8859-x adalah karakter ke 0 s.d 127 untuk karakter ASCII sedangkan sisanya karakter tambahan. contoh:
Untuk mengatasi hal tersebut, perlu dikembangkan suatu character set yang dapat menampung sekaligus banyak karakter, tidak hanya 256, jika perlu dapat menampung semua karakter yang digunakan oleh semua bahasa di dunia ini, dan yang pasti tidak mungkin bisa menggunakan sistem single byte encoding.
Dilatarbelakangi hal tersebut muncullah Unicode Character Set yang dikembangkan oleh Unicode Consortium.
Saat ini Unicode dapat mengcover lebih dari 1.100.000 karakter, angka tersebut sangat cukup untuk mengakomodasi semua karakter yang digunakan semua bahasa di dunia ini.
Dari waktu kewaktu, karakter baru terus ditambahkan, tidak hanya bahasa resmi negara tetapi juga bahasa daerah termasuk aksara jawa, Bali Bugis, Sunda, dll
Sampai dengan saat ini (Unicode Versi 8.o – di release 17 Juni 2015) jumlah karakter yang ditambahkan baru sebanyak 120.737, sehingga baru terpakai sekitar 12% dari kapasitas yang ada, masih sisa tersisa 88% yang masih sangat cukup untuk penggunaan jangka panjang.
Dengan perkembangan yang ada dapat dikatakan bahwa unicode characterset is the last character set. Waktu yang akan membuktikannya.
Sistem encoding ini sama dengan yang digunakan pada UCS-2 (2-byte Universal Character Set) – didefinisikan oleh ISO 10646, yang sudah terlebih dahulu diperkenalkan.
Pada generasi awal unicode ini belum dikenal istilah UTF-16 karena memang hanya satu sistem encoding yang digunakan.
Dengan basis 16 bit, karakter yang ditampung mencapai 65.536 karakter (216), sistem tersebut berlangsung hingga Unicode versi 1.1.0 (1991 s.d 1995).
Semakin lama sistem encoding yang ada tidak cukup menampung karakter baru yang belum ditambahkan, oleh karena itu diperkenalkanlah UTF-16 atau disebut juga Extended UCS-2 yang direlease tahun 1996.
UTF-16 merupakan sistem variable length encoding yang berarti setiap code point (kode yang mencerminkan suatu karakter) di encode menggunakan satu atau dua kali 16-bit (1 code unit = 16 bit).
Sederhananya setiap karakter unicode di encode menjadi 16 bit (1 code unit) atau 32 bit (2 code unit) tergantung jenis karakternya.
16 bit pertama digunakan untuk mengencode karakter yang ada pada Basic Multilanguage Plane BMP (karakter ke 0 s.d 65.535), sedangkan 16 bit berikutnya digunakan untuk mengencode karakter tambahan.
BPM sudah mencakup sangat banyak karakter dan simbol, mulai dari bahasa yang umum hingga yang rumit seperti CJK (China, Jepang, Korea), disamping itu juga sudah menampung aksara daerah dari berbagai negara, seperti yang ada di kita: aksara Jawa (Unicode versi 5.2), Bali, Sunda dan Batak.
Perbedaan karakter yang dapat diencode oleh UTF-16 dan UCS-2 tampak seperti pada tabel berikut:
Keuntungan penggunaan UTF-16 adalah karakter pada BMP
diencode menggunakan sistem fixed length 16bit,
sehingga mudah untuk diindex (mendukung byte order dependent), tidak seperti
pada utf8 yang menggunakan 8 s.d 24 bit.
Meski demikian, karakter yang semestinya bisa diencode menggunakan sistem 8 bit, harus diencode menggunakan sistem 16 bit, seperti pada karakter ASCII, yang artinya yang seharusnya bisa disimpan menggunakan ruang 1 byte dipaksa menggunakan 2 byte, sehingga UTF-16 ini cocok digunakan pada aplikasi yang mementingkan speed dan tidak mempermasalahkan ruang penyimpanan.
Kelemahan lain adalah sama sekali tidak mendukung karakter ASCII, karena jelas sistem encoding yang digunakan berbeda, sehingga karakter yang disimpan dengan sistem encoding ASCII tidak dapat dibuka oleh aplikasi yang menggunakan sistem encoding UTF-16.
Saat ini UTF-16 masih populer digunakan, diantaranya: bahasa pemrograman Java, C#, Objective C dan Windows API
Angka 32 pada UTF berarti 32 bit dan 4 pada UCS berarti 4 byte, yang dapat diartikan bahwa space yang digunakan untuk menyimpan suatu karakter adalah 4 byte atau 32 bit.
UTF-32 merupakan alternatif dari UTF-16, jika pada UTF-16 terdapat penggunaan sistem doubel 16 bit (untuk karakter ke 65.535 keatas), UTF-32 menggunakan fixed – width encoding, dengan base 32 bit (1 code unit = 32 bit), dimana semua karakter disimpan menggunakan sistem 32 bit encoding.
Akibatnya setiap karakter membutuhkan ruang penyimpanan sebesar 4 byte (32 bit), meskipun sebenarnya terdapat karakter yang hanya menggunakan 8 bit, sehingga pada UTF-32, yang terisi hanya 8 bit pertama, sisanya bernilai 0.
Dengan model encoding seperti ini, binary dapat diindex/diurutkan (mendukung byte order dependent) – seperti pada ASCII, sehingga pencarian suatu karakter dapat dilakukan lebih cepat.
Meski demikian encoding ini memiliki kelemahan yaitu memakan banyak space dan memory, yang tentu saja tidak efisien, contoh kata halo pada UTF-32 membutuhkan ruang penyimpanan 16 byte, sedangkan pada ASCII cukup 4 byte.
Contoh karakter dan nilai binary nya pada UTF-32:
karena semua karakter diencode pada 32 bit maka karakter yang sering
digunakan pun (karakter ke 0 s.d 65536) yang ada di BMP juga akan disimpan
sebesar 4 byte yang tentu saja lebih efisien menggunakan UTF-16 karena
hanya membutuhkan ruang penyimpanan 2 byte. Oleh karena itu penggunaan UTF-32
saat ini sudah jarang ditemui.
UTF-8 menggunakan sistem variable length encoding dengan basis 8 bit (1 code unit = 8bit), angka ini tercermin pada angka 8 yang berada di belakang UTF.
Sistem variable length berarti karakter di encoding menggunakan pola tertentu dengan panjang bit tidak tetap tergantung jenis karakternya, bisa 8, 16, 24 atau 32 bit. Pembagian penggunaan bit adalah sebagai berikut:
Pada UTF-8 sistem 1 byte encoding yang digunakan sama persis dengan sistem yang digunakan pada ASCII sehingga UTF-8 kompatibel dengan karakter ASCII, yang artinya karakter yang disimpan menggunakan sistem encoding ASCII dapat dibuka menggunakan sistem encoding UTF.
Perbandingan bit yang digunakan
Perbandingan bit yang digunakan pada ketiga sistem encoding yang ada pada Unicode Standar tampak seperti pada tabel berikut:
Pada awal munculnya ASCII standard hingga ISO-8859-x istilah character set dan sistem encoding merujuk ke standar itu sendiri, misal istilah ASCII Character Set digunakan untuk menyebut character set yang digunakan ASCII, dan ASCII encoding untuk menyebut sistem encoding pada ASCII.
Meskipun sebenarnya istilah ASCII lebih tepat digunakan untu character set, begitu juga dengan ISO-8958-1 atau Latin1 standar.
Pada awal muncul Unicode standar pun, istilah yang sama masih masih dapat digunakan, namun setelah muncul UTF-16, istilah character set dan sistem encoding mulai agak membingungkan
Banyak yang menyebut UTF sebagai character set dan Unicode adalah sistem encoding padahal sebenarnya UTF adalah sistem encoding dan Unicode lebih tepat digunakan untuk menyebut character set, walaupun Unicode sendiri hanya merupakan suatu standar.
Contoh pada dokumen HTML sering kita jumpai meta tag berikut:
<meta Content-Type: text/html; charset=utf-8>
Dalam mengartikan tag diatas, mungkin beberapa orang menganggap bahwa
Hal yang sama juga terjadi pada istilah dalam dunia database, seperti MySQL yang menyebut utf8, utf16, utf32 dan utf8mb4 sebagai character set.
Character set pertama adalah ASCII yang diperkenalkan tahun 1960, sejak itu muncul berbagai character set yang semuanya ditujukan untuk menampung karakter yang dibutuhkan namun terbatas hanya untuk regional tertentu dan tujuan tertentu.
Tahun 1991 mulai diperkenalkan Unicode Standar atau sering disebut Unicode Character Set yang dapat menampung semua karakter yang ada baik yang sudah ada pada character set lain maupun yang belum terdefinisi, dan hingga saat ini Unicode merupakan satu standar yang paling banyak digunakan terutama untuk pertukaran data di internet
1. Tipe Data Dasar
Sesuai dengan namanya, tipe data dasar adalah tipe data paling dasar yang tersedia di dalam bahasa pemrograman C. Terdapat 3 jenis tipe data dasar:
2. Tipe Data Turunan
Tipe data turunan berasal dari tipe data dasar yang dikelompokkan atau di modifikasi. Terdapat 3 tipe data turunan di dalam bahasa pemrograman C:
3. Tipe Data Bentukan (enum)
Sesuai dengan namanya, tipe data bentukan adalah tipe data yang dibuat sendiri oleh kita (programmer). Isinya berupa data-data yang sudah ditentukan. Tipe data bentukan ini dikenal juga sebagai Enumerated Data Type atau disingkat sebagai enum.
4. Tipe Data Void
Tipe data void adalah tipe data khusus yang menyatakan tidak ada data. Penggunaannya khusus untuk beberapa situasi seperti function yang tidak mengembalikan nilai (return void), atau mengisi argumen function dengan nilai kosong.
Tanpa pengelompokan, berikut ke-8 tipe data dalam bahasa pemrograman C:
Bahasa C memang tidak memiliki tipe boolean bawaan, tapi bisa diakali dengan membuatnya menggunakan tipe data bentukan (enum), atau menggunakan library khusus: stdbool.h.
Sedangkan untuk string, di dalam bahasa C termasuk ke dalam array. String di defenisikan sebagai array dari tipe data char.
Bisa juga dibilang sebagai variabel yang tidak bisa diubah nilainya.
Ada dua cara pembuatan konstanta pada C:
Pada
Pada
Posisi penulisan untuk
Oh iya, untuk nama konstanta disarankan menggunakan huruf kapital untuk menandakan itu sebuah konstanta.
Apa yang akan terjadi jika saya mencoba mengisi nilai ke dalam konstanta?
Ya programnya akan error.
Increment adalah operasi bilangan dimana bilangan hasil merupakan bilangan asal ditambah satu, sedangkan decrement adalah operasi bilangan dimana bilangan hasil merupakan bilangan asal dikurang satu.
I.
Langkah dalam Membuat Bahasa C
Misal membuat Hello World:
Menulis Program Bahasa C1. Pertama teman-teman buka dulu text editor nya, kalau di linux (gedit) di windows (notepad/notepad++) atau bisa juga memakai compiler yang lain yang ada pada windows seperti Dev C++ atau CodeBlock. Kalau masih bingung mengenai text editor atau compiler silahkan baca Pengenalan Bahasa C.

Tampilan Text Editor (Gedit) di Ubuntu

Tampilan text Editor setelah di save dengan .c
#include<stdio.h>
int main(){
printf(“Hello World !! \n”);
}
·
kata #include<stdio.h> adalah
perintah untuk menginputkan fungsi2 yang ada di library :<stdio.h>
agar bisa kita gunakan dalam menulis program.
·
int main() adalah sebuah main
program(kepala program) kita yang mana berbentuk integer(int) dengan di ikuti
kata main dan tanda () biasanya digunakan untuk membuat sebuah
parameter2 bila program kita sudah banyak. Karena kita hanya ingin menampilkan
“hello world” maka kita kosong kan saja.
catatan : “ kata main() harus kita buat kalau tidak maka program kita
akan Eror, sedangkan kata int sifatnya opsional bisa kita kosongkan ataupun
kita ganti dengan float,double tergantung program yang seperti apa yang
akan kita buat. Tetapi saya akan terus membuat int main() agar lebih mudah
memahaminya”.
·
Tanda {} adalah bahwasanya program kita
harus kita buat di dalam tanda kurung kurawal tersebut agar bisa di compile.
·
Printf adalah perintah untuk menampilkan
sesuatu ke layar. Jadi jika kita buat printf(“Hello World !! \n”); artinya kita
membuat perintah untuk menamiplkan kata Hello World !! ke layar.
4. Program kita telah selesai kita buat, langkah terakhir
adalah tinggal menjalankannya.Catatan : “Kalau memakai Dev C++ atau Codeblock maka tinggal mengcompilenya saja dengan menekan tombol run,maka hasilnya akan muncul”
5. Karena saya memakai text Editor, maka kita mengcompile nya menggunakan terminal di ubuntu atau cmd diwindows.
·
Buka Terminal atau Cmd kalau di windows.
·
Setelah itu masuk ke direktori folder
tempat file hello.c yang kita simpan tadi, contohnya seperti berikut :
* saya menyimpannya di document, ketik perintah :
cd (namafolder)
II.
Struktur Bahasa C
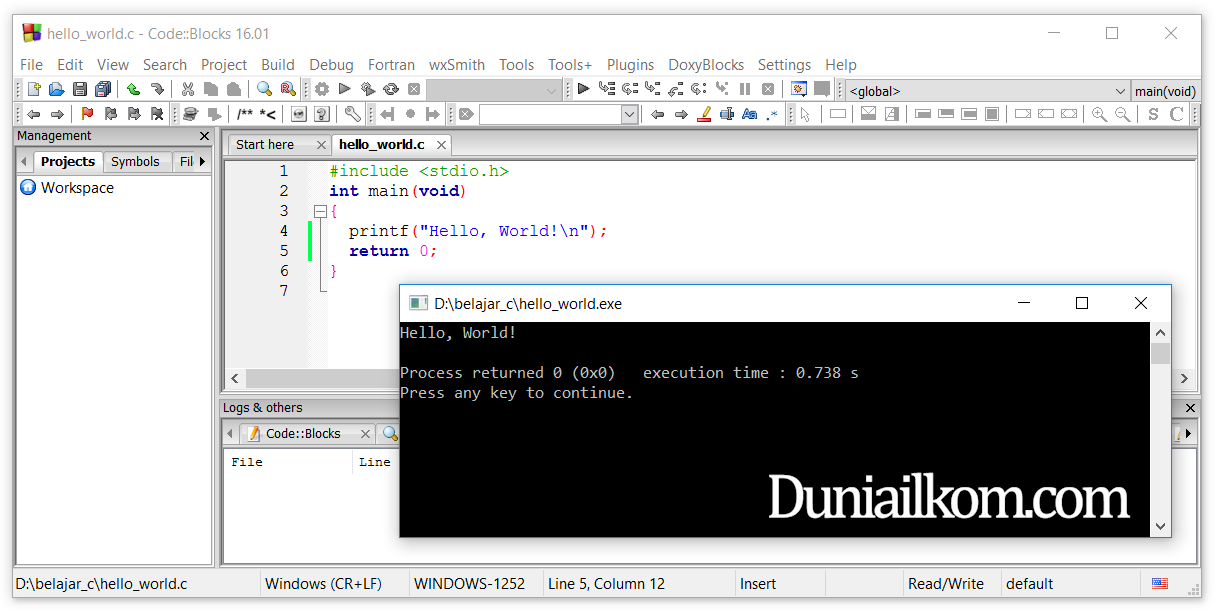
Kode
program yang telah jalankan sebelumnya sangat sederhana, tapi sudah mewakili
struktur dasar dari sebuah bahasa pemrograman C. Berikut kode program tersebut:
#include <stdio.h>
int
main(void)
{
printf("Hello,
World!\n");
return 0;
}
 |
{kind=link}
#include <stdio.h>
Di
baris paling awal, terdapat kode #include. Perintah #include
digunakan untuk memasukkan sebuah file khusus yang memungkinkan kita mengakses
berbagai fitur tambahan dalam bahasa C.
Dalam
contoh diatas, file stdio.h berisi kode program agar nantinya kita bisa
mengakses perintah printf. File stdio.h sendiri merupakan singkatan
dari Standard Input/Output.
Dengan
kata lain, agar di dalam kode program nanti kita bisa menggunakan perintah printf,
dibagian paling atas kode program C harus terdapat baris #include
<stdio.h>. File include ini juga sering disebut sebagai header
file, dan karena itu pula menggunakan akhiran .h.
Bahasa
C menerapkan konsep modular, dimana fitur-fitur yang ada di pecah ke
berbagai file. Jika ingin menggunakan perintah tertentu, panggil header file
yang sesuai.
Hasilnya,
ukuran file program yang ditulis menggunakan bahasa C menjadi efisien. Kita
hanya perlu menggunakan header file yang dibutuhkan saja. Namun kebalikannya,
setiap ingin menggunakan perintah tertentu, harus men-include-kan file header
yang dibutuhkan.
int main(void) { }
Satu-satunya
perintah yang harus ada di setiap kode program bahasa C adalah main().
Struktur
main() sendiri pada dasarnya merupakan sebuah fungsi (function).
Isi dari function ini diawali dan diakhiri dengan tanda kurung kurawal ” { ”
dan ” } “. Di dalam tanda kurung inilah “isi” dari kode program penyusun fungsi
main() ditulis.
Kode
int sebelum main() menandakan nilai kembalian atau hasil
akhir dari function main(). Kode int merupakan singkatan dari integer,
yakni tipe data angka bulat.
Dengan
demikian, kode program main() yang saya tulis diatas harus menghasilkan
sebuah angka bulat (menggunakan perintah return yang akan kita bahas
sesaat lagi).
Sedangkan
tambahan void ke dalam main(void) menandakan bawah fungsi main()
tidak membutuhkan nilai input (bahasa inggris void = kosong).
*
Jika anda agak bingung dengan penjelasan ini, bisa dianggap bahwa int
main(void) { } adalah perintah yang mengawali setiap kode program bahasa C.
printf(“Hello, World!\n”);
Perintah
printf digunakan untuk menampilkan sesuatu ke layar. Perintah ini
merupakan bagian dari stdio.h, sehingga jika kita ingin menggunakannya,
harus terdapat baris perintah #include <stdio.h> di bagian paling
awal kode program bahasa C.
Teks
yang ingin ditampilkan ditulis dalam tanda kurung dan di dalam tanda kutip dua,
seperti: printf(“Hello, World!\n”); Hasil dari perintah ini, akan tampil
teks Hello, World! di layar. Tapi apa fungsi tambahan karakter \n?
Jika
ditulis di dalam teks, karakter ” \ ” dikenal sebagai escape character.
Fungsinya untuk menampilkan karakter yang tidak bisa ditulis. Sebagai contoh, \n
merupakan perintah untuk menulis newline character, yakni karakter
penanda baris baru.
Artinya,
perintah printf(“Hello, World!\n”) akan menampilkan teks “Hello,
World!”, kemudian pindah ke baris baru. Bahasa C mendukung berbagai escape
character yang nantinya juga akan kita pelajari.
Setelah
tanda kurung penutup perintah printf, harus ditutup dengan tanda titik
koma (semi-colon), yakni tanda “ ; ”. Setiap perintah bahasa C, harus
diakhiri dengan tanda ini, kecuali beberapa perintah khusus. Lupa menambahkan
tanda titik koma di akhir sebuah perintah merupakan error yang sangat sering
terjadi.
return 0;
Perintah
return 0; berhubungan dengan kode int main(void) sebelumnya.
Disinilah kita menutup function main() yang sekaligus mengakhiri
kode program bahasa C.
Return
0 artinya kembalikan nilai 0
(nol) ke sistem operasi yang menjalankan kode program ini. Nilai 0 menandakan
kode program berjalan normal dan tidak ada masalah (EXIT_SUCCESS).
Kita
juga bisa menulis return 1, return 99, return -1, dll. Nilai-nilai ini nantinya
bisa digunakan oleh sistem operasi atau program lain. Nilai return selain 0
dianggap terjadi error atau sesuatu yang salah (EXIT_FAILURE).
Apakah
perintah Return 0 ini harus ditulis?
Harus ditulis! jika kita berpatokan ke struktur bahasa C yang ideal.
Namun beberapa compiler (termasuk Code:Blocks yang saya gunakan), akan
“memaafkan” jika perintah ini tidak ditulis dan menambahkan perintah return 0 secara
otomatis (tidak disarankan).
III.
Contoh Bahasa C
Program Pemilihan 2 Kasus
Pemilihan 2 kasus menggunakan perintah if
then else. Pada dasarnya pemilihan dua kasus sama seperti pemilihan 1
kasus. Pada pemilihan 2 kasus “Jika kondisi terpenuhi atau bernilai benar, maka
aksi pertama akan ditampilkan. Namun, jika kondisi tidak terpenuhi atau
bernilai salah, maka aksi kedua akan ditampilkan. Berikut contoh programnya,
// Program Pemilihan 2 kasus
#include <stdio.h>
int main()
{
int Angka;
printf("Masukkan sebuah bilangan : ");
scanf("%d",&Angka);
if(Angka >0)// Pemilihan 1 Kasus
{ printf("Angka yang Anda masukkan adalah : POSITIF");
// Statement Benar akan ditampilkan } else { printf("Angka yang Anda masukkan adalah : NEGATIF");
// Statement Salah akan ditampilkan } return0;
}
Berikut output program di atas :
Program Pemilihan 3 Kasus
Menggunakan perintah if then bertingkat
Perintah ini digunakan untuk menguji kondisi
lebih dari 2 kasus. Jika salah satu kondisi terpenuhi, akan ditampilkan pada
layar monitor. Berikut contoh programnya,
// Program pemilihan 3 kasus menggunakan if bertingkat
#include <stdio.h>
int main () {
int Angka;printf("Masukkan sebuah Angka : ");
scanf("%d",&Angka);
if(Angka >0){
printf("Angka yang Anda masukkan POSITIF");
// Pernyataan jika Angka > 0 }elseif(Angka <0){
printf("Angka yang Anda masukkan adalah NEGATIF");
// Pernyataan jika Angka < 0 }else{
printf("Angka yang Anda masukkan adalah NOL");
// Pernyataan lainnya } return0;
}
Berikut output program di atas :
KOMPONEN BAHASA C
A.
Character
Set
Character Set ASCII
Pada awal generasi digunakannya sistem komputer, ASCII Character Set yang mulai ada sejak 1960-an menjadi standar yang digunakan di sebagian besar sistem komputer untuk menampilkan karakter.ASCII merupakan kependekan dari American Standard Code for Information Interchange, sehingga dapat ditebak bahwa ASCII ini dibuat oleh Amerika, yang memang ditujukan untuk mengakomodasi karakter yang digunakan pada bahasa mereka dan oleh sebab itu ASCII generasi pertama ini sering disebut US-ASCII.
Character Set ASCII hanya terdiri dari 128 karakter yang terdiri dari karakter nyata (huruf, angka, simbol dan tanda baca) dan karakter tidak nyata (tab, enter, alt, dsb), contoh karakter ASCII adalah seperti yang ada pada tombol keyboard yang kita gunakan sekarang ini, untuk lebih lengkapnya dapat dilihat pada tabel ini.
Kenapa hanya 128 karakter? ya karena memang pada saat itu hanya karakter tersebut yang diperlukan dan sistem yang ada hanya dapat menampung sejumlah karakter terebut dan sampai dengan saat ini saya rasa masih cukup memadahi.
Setiap karakter yang ada pada ASCII cukup ditampung kedalam 7 bit binary digit, sehingga dapat dikatakan ASCII menggunakan 7 bit sistem encoding, contoh:
Karakter
|
Binary
|
Karakter
|
Binary
|
a
|
1100001
|
@
|
1000000
|
b
|
1100010
|
#
|
0100011
|
c
|
1100011
|
%
|
0100101
|
1
|
0110001
|
!
|
0100001
|
2
|
0110010
|
$
|
0100100
|
3
|
0110011
|
&
|
0100110
|
Character Set Latin-1 atau ISO/IEC 8859-1
Semakin berkembangnya penggunaan komputer dan internet, maka negara-negara maju lain di Eropa khususnya yang menggunakan karakter khusus seperti penggunaan accent (tanda diatas karakter) yang digunakan di negara Jerman, Swedia, Prancis, Belanda, dll merasakan keterbatasan ASCII.Hal tersebut karena dengan ASCII, mereka tidak dapat menggunakan karakter yang ada pada bahasa mereka, sehingga pertukaran data tidak dapat dilakukan dengan baik.
Permasalahan tersebut menjadi isu penting dan akhirnya pada tahun 1987 direlease versi pertama dari ISO-8859-1 atau Latin1 (beberapa ada yang menggunakan istilah Extended ASCII, 8 bit ASCII atau ASCII – bukan US-ASCII) yang diadopsi dari ECMA Standard (European Computer Manufacturers Association).
Angka 1 pada ISO-8859-1 berarti standard encoding pertama dari seri ISO-8859 yang terdaftar di ISO.
Karakter yang ada pada ISO-8859-1 hanya terdiri dari karakter ASCII ditambah dengan beberapa karakter yang khusus digunakan di bahasa negara-negara Eropa Barat, penambahan ini dimulai dari karakter ke 128 s.d 255.
Kenapa 128 bukan 129? bukankah ASCII jumlah karakternya 128? ya betul, ASCII jumlah karakternya 128, namun urutan karakter dimulai dari 0, sehingga penghitungan karakter dimulai dari 0.
Karakter yang ada pada ISO-8859-1 dapat dilihat di http://www.ascii-code.com/
Karakter pada Latin1 tetap berukuran 1 byte, karena seperti disebutkan sebelumnya bahwa masih terdapat 1 bit tersisa pada sistem encoding ASCII, penggunaan 1 bit ini berdampak bertambahnya kombinasi bilangan biner sehingga dalam sistem 8 bit dapat diperoleh karakter berjumlah 256(2^8).
Penggunaan 1 byte ini disebut juga single byte encoding. Berikut ini contoh karakter Latin1 dan nilai binary nya:
TEXT
|
ASCII
|
BINARY
|
TEXT
|
ASCII
|
BINARY
|
ä
|
chr(228)
|
11100100
|
ø
|
chr(248)
|
11111000
|
å
|
chr(229)
|
11100101
|
ù
|
chr(249)
|
11111001
|
æ
|
chr(230)
|
11100110
|
ú
|
chr(250)
|
11111010
|
ç
|
chr(231)
|
11100111
|
ý
|
chr(253)
|
11111101
|
è
|
chr(232)
|
11101000
|
þ
|
chr(254)
|
11111110
|
é
|
chr(233)
|
11101001
|
ÿ
|
chr(255)
|
11111111
|
Munculnya Latin1 ini ternyata belum dapat mengatasi keterbatasan penggunaan karakter, seperti penggunaan karakter di negara negara Eropa Tengah dan Timur, oleh karena itu perlu dikembangkan character set lain yang dapat mengakomodasi karakter tersebut.
Mulailah bermunculanlah character set baru yang diberi nama ISO-8859-2 atau Latin2, ISO-8859-3 atau Latin3, dan seterusnya hingga ISO-8859-16 yang direlease tahun 2001. Masing masing character set spesifik untuk bahasa tertentu dan tujuan tertentu. Untuk detail seri ISO 8859 dapat dibaca di wikipedia.
Secara umum format character set ISO-8859-x adalah karakter ke 0 s.d 127 untuk karakter ASCII sedangkan sisanya karakter tambahan. contoh:
Encoding
|
#0 – #127
|
#128 – #255
|
ISO-8859-5
|
ASCII
|
Cyrillic
|
ISO-8859-6
|
ASCII
|
Arabic
|
ISO-8859-7
|
ASCII
|
Greek
|
ISO-8859-8
|
ASCII
|
Hebrew
|
Unicode (character set terakhir?)
Seperti pembahasan diatas, ternyata terdapat banyak sekali character set, masing masing dikembangkan hanya untuk penggunaan pada regional tertentu, dan untuk tujuan tertentu, tidak ada character set yang dapat menampung semua karakter yang digunakan oleh semua bahasa.
Hal ini terjadi karena sistem encoding yang dikembangkan masih menggunakan sistem single byte (8 bit) dimana hanya dapat menampung karakter sebanyak 256.Untuk mengatasi hal tersebut, perlu dikembangkan suatu character set yang dapat menampung sekaligus banyak karakter, tidak hanya 256, jika perlu dapat menampung semua karakter yang digunakan oleh semua bahasa di dunia ini, dan yang pasti tidak mungkin bisa menggunakan sistem single byte encoding.
Dilatarbelakangi hal tersebut muncullah Unicode Character Set yang dikembangkan oleh Unicode Consortium.
Saat ini Unicode dapat mengcover lebih dari 1.100.000 karakter, angka tersebut sangat cukup untuk mengakomodasi semua karakter yang digunakan semua bahasa di dunia ini.
Dari waktu kewaktu, karakter baru terus ditambahkan, tidak hanya bahasa resmi negara tetapi juga bahasa daerah termasuk aksara jawa, Bali Bugis, Sunda, dll
Sampai dengan saat ini (Unicode Versi 8.o – di release 17 Juni 2015) jumlah karakter yang ditambahkan baru sebanyak 120.737, sehingga baru terpakai sekitar 12% dari kapasitas yang ada, masih sisa tersisa 88% yang masih sangat cukup untuk penggunaan jangka panjang.
Dengan perkembangan yang ada dapat dikatakan bahwa unicode characterset is the last character set. Waktu yang akan membuktikannya.
Character Set UTF-16 dan UCS-2
Pada awal generasi Unicode Standard (versi 1.0.0), diperkenalkan character set yang mampu menampung karakter lebih dari 256, saat itu digunakan sistem fixed width encoding dengan basis 16 bit (2 x 8 bit) atau disebut dengan istilah double byte encoding.Sistem encoding ini sama dengan yang digunakan pada UCS-2 (2-byte Universal Character Set) – didefinisikan oleh ISO 10646, yang sudah terlebih dahulu diperkenalkan.
Pada generasi awal unicode ini belum dikenal istilah UTF-16 karena memang hanya satu sistem encoding yang digunakan.
Dengan basis 16 bit, karakter yang ditampung mencapai 65.536 karakter (216), sistem tersebut berlangsung hingga Unicode versi 1.1.0 (1991 s.d 1995).
Semakin lama sistem encoding yang ada tidak cukup menampung karakter baru yang belum ditambahkan, oleh karena itu diperkenalkanlah UTF-16 atau disebut juga Extended UCS-2 yang direlease tahun 1996.
UTF-16 merupakan sistem variable length encoding yang berarti setiap code point (kode yang mencerminkan suatu karakter) di encode menggunakan satu atau dua kali 16-bit (1 code unit = 16 bit).
Sederhananya setiap karakter unicode di encode menjadi 16 bit (1 code unit) atau 32 bit (2 code unit) tergantung jenis karakternya.
16 bit pertama digunakan untuk mengencode karakter yang ada pada Basic Multilanguage Plane BMP (karakter ke 0 s.d 65.535), sedangkan 16 bit berikutnya digunakan untuk mengencode karakter tambahan.
BPM sudah mencakup sangat banyak karakter dan simbol, mulai dari bahasa yang umum hingga yang rumit seperti CJK (China, Jepang, Korea), disamping itu juga sudah menampung aksara daerah dari berbagai negara, seperti yang ada di kita: aksara Jawa (Unicode versi 5.2), Bali, Sunda dan Batak.
Perbedaan karakter yang dapat diencode oleh UTF-16 dan UCS-2 tampak seperti pada tabel berikut:
Encoding
|
#0 – #65535
|
> 65.535
|
UTF-16
|
BPM
|
Karakter
Lain
|
UCS-2
|
BPM
|
–
|
Meski demikian, karakter yang semestinya bisa diencode menggunakan sistem 8 bit, harus diencode menggunakan sistem 16 bit, seperti pada karakter ASCII, yang artinya yang seharusnya bisa disimpan menggunakan ruang 1 byte dipaksa menggunakan 2 byte, sehingga UTF-16 ini cocok digunakan pada aplikasi yang mementingkan speed dan tidak mempermasalahkan ruang penyimpanan.
Kelemahan lain adalah sama sekali tidak mendukung karakter ASCII, karena jelas sistem encoding yang digunakan berbeda, sehingga karakter yang disimpan dengan sistem encoding ASCII tidak dapat dibuka oleh aplikasi yang menggunakan sistem encoding UTF-16.
Saat ini UTF-16 masih populer digunakan, diantaranya: bahasa pemrograman Java, C#, Objective C dan Windows API
Character Set UTF-32 atau UCS-4
UTF-32 secara resmi menjadi bagian dari Unicode standar pada versi 3.1.0 yang dipublikasikan tahun 2001, sistem encoding ini sama dengan yang digunakan pada UCS-4 (4-byte Universal Character Set) – didefinisikan oleh ISO 10646, yang sudah terlebih dahulu diperkenalkan.Angka 32 pada UTF berarti 32 bit dan 4 pada UCS berarti 4 byte, yang dapat diartikan bahwa space yang digunakan untuk menyimpan suatu karakter adalah 4 byte atau 32 bit.
UTF-32 merupakan alternatif dari UTF-16, jika pada UTF-16 terdapat penggunaan sistem doubel 16 bit (untuk karakter ke 65.535 keatas), UTF-32 menggunakan fixed – width encoding, dengan base 32 bit (1 code unit = 32 bit), dimana semua karakter disimpan menggunakan sistem 32 bit encoding.
Akibatnya setiap karakter membutuhkan ruang penyimpanan sebesar 4 byte (32 bit), meskipun sebenarnya terdapat karakter yang hanya menggunakan 8 bit, sehingga pada UTF-32, yang terisi hanya 8 bit pertama, sisanya bernilai 0.
Dengan model encoding seperti ini, binary dapat diindex/diurutkan (mendukung byte order dependent) – seperti pada ASCII, sehingga pencarian suatu karakter dapat dilakukan lebih cepat.
Meski demikian encoding ini memiliki kelemahan yaitu memakan banyak space dan memory, yang tentu saja tidak efisien, contoh kata halo pada UTF-32 membutuhkan ruang penyimpanan 16 byte, sedangkan pada ASCII cukup 4 byte.
Contoh karakter dan nilai binary nya pada UTF-32:
TEXT
|
Chr Ke
|
BINARY
|
!
|
32
|
00000000
00000000 00000000 00100001
|
Љ
|
1025
|
00000000
00000000 11111001 01100101
|
65.537
|
00000000
00000010 00100111 01001000
|
Character Set dan Character Encoding Utf-8
Generasi terakhir dari sistem encoding UTF adalah UTF-8. UTF-8 resmi masuk ke Unicode Standar pada versi 5.0.0 (2006). Sistem encoding UTF-8 hingga saat ini paling banyak digunakan untuk pertukaran data, terutama pada media internet, yang hingga saat ini sudah mencapai angka 85.3% (27 Oktober 2015) dan akan terus meningkat.UTF-8 menggunakan sistem variable length encoding dengan basis 8 bit (1 code unit = 8bit), angka ini tercermin pada angka 8 yang berada di belakang UTF.
Sistem variable length berarti karakter di encoding menggunakan pola tertentu dengan panjang bit tidak tetap tergantung jenis karakternya, bisa 8, 16, 24 atau 32 bit. Pembagian penggunaan bit adalah sebagai berikut:
- 8 bit (1 byte) encoding digunakan untuk karakter 0 s.d 127, sama persis dengan yang digunakan ASCII.
- 16 bit (2 byte) encoding digunakan untuk karakter 128 s.d 2047. Contoh: Huruf Latin Extended (dengan tilde (Ã), macron (¯), acute(Á), grave(À) dan accents (tanda diatas huruf) lainnya), huruf kirilitz (cyrillic) yang digunakan beberapa negara Slavia: Rusia, Ukraina, Bulgaria dan Serbia (Contoh: КАЛИФОРНИЯ) , Yunani (Greek), contoh: μαγεια, Armenia, Ibarani (Hebrew), contoh: הוא עובד, Arab contoh: اللغة العربية, dan lainnya.
- 24 bit (3 byte) encoding digunakan untuk karakter 2048 s.d 65.535. Contoh huruf Cina, Jepang dan Korea.
- 32 bit (4 byte) encoding untuk karakter 65.536 s.d 1,112,064
Pada UTF-8 sistem 1 byte encoding yang digunakan sama persis dengan sistem yang digunakan pada ASCII sehingga UTF-8 kompatibel dengan karakter ASCII, yang artinya karakter yang disimpan menggunakan sistem encoding ASCII dapat dibuka menggunakan sistem encoding UTF.
Perbandingan bit yang digunakan
Perbandingan bit yang digunakan pada ketiga sistem encoding yang ada pada Unicode Standar tampak seperti pada tabel berikut:
Range (Hexadecimal)
|
Range (Decimal)
|
UTF-8
|
UTF-16
|
UTF-32
|
000000
– 00007F
|
0-127
|
1
|
2
|
4
|
000080
– 00009F
|
128-2.047
|
2
|
||
0000A0
– 0003FF
|
||||
000400
– 0007FF
|
||||
000800
– 003FFF
|
2.048-65.535
|
3
|
||
004000
– 00FFFF
|
||||
010000
– 03FFFF
|
65.536-1.114.111
|
4
|
4
|
|
040000
– 10FFFF
|
Ambiguitas Character Set dan Caharacter Encoding
Dari uraian diatas secara jelas dapat kita bedakan apa itu character set dan apa itu sistem encoding, namun kenyataannya terkadang kedua istilah ini membingungkan.Pada awal munculnya ASCII standard hingga ISO-8859-x istilah character set dan sistem encoding merujuk ke standar itu sendiri, misal istilah ASCII Character Set digunakan untuk menyebut character set yang digunakan ASCII, dan ASCII encoding untuk menyebut sistem encoding pada ASCII.
Meskipun sebenarnya istilah ASCII lebih tepat digunakan untu character set, begitu juga dengan ISO-8958-1 atau Latin1 standar.
Pada awal muncul Unicode standar pun, istilah yang sama masih masih dapat digunakan, namun setelah muncul UTF-16, istilah character set dan sistem encoding mulai agak membingungkan
Banyak yang menyebut UTF sebagai character set dan Unicode adalah sistem encoding padahal sebenarnya UTF adalah sistem encoding dan Unicode lebih tepat digunakan untuk menyebut character set, walaupun Unicode sendiri hanya merupakan suatu standar.
Contoh pada dokumen HTML sering kita jumpai meta tag berikut:
<meta Content-Type: text/html; charset=utf-8>
Dalam mengartikan tag diatas, mungkin beberapa orang menganggap bahwa
charset="utf-8" maksudnya
adalah character set yang digunakan adalah UTF-8, padahal sebenarnya yang dimaksud
disini adalah sistem encoding yang digunakan adalah UTF-8.Hal yang sama juga terjadi pada istilah dalam dunia database, seperti MySQL yang menyebut utf8, utf16, utf32 dan utf8mb4 sebagai character set.
Jadi Character Set mana yang sebaiknya digunakan?
Berdasarkan uraian diatas, selanjutnya muncul pertanyaan, jadi sebaiknya character set mana yang sebaiknya digunakan? hal ini tergantung dari jenis karakter yang akan kita digunakan, beberapa kemungkinan yang ada:- Aplikasi/website yang kita bangun menggunakan satu bahasa/beberapa berbahasa yang hanya menggunakan jenis huruf alphabet biasa (seperti Bahasa Indonesia atau Bahasa Inggris), maka cukup menggunakan character set ASCII (ascii pada MysQL) atau ISO-8859-1 (Latin1 pada MySQL).
Kenapa tidak utf8? bukankan utf8 juga
menyimpannya sebesar 1 byte?
Hal ini tergantung dari sistem
penyimpanan yang kita gunakan, pada database tertentu seperti MySQL penggunaan
utf8 memungkinkan penggunaan ruang penyimpanan lebih dari 1 byte tergantung
tipe data yang digunakan, sedangkan Latin1, ASCII, dan sejenisnya pasti
menggunakan ruang 1 byte.
- Bahasa yang kita gunakan menggunakan bahasa tertentu, misal bahasa Arab, maka dapat menggunakan character set ISO-8859-6 yang memang di desain untuk penggunaan arabic alphabet namun tidak termasuk character tambahan seperti yang digunakan pada alphabet bahasa Urdu dan Persia.
Namun jika character mengandung
character urdu seperti pada quran dan hadis, character set tersebut
tidak bisa digunakan lagi karena character yang digunakan lebih kompleks,
seperti ( لاگا,
شيرِ),
sehingga pilihannya utf-16 atau utf-8.
Pada utf-16 character ini di encode
menggunakan sistem 2 byte dan 3 byte pada utf-8, sehingga lebih efisien
menggunakan utf-16.
- Aplikasi yang kita kembangkan ditujukan untuk pengguna seluruh dunia (world wide) sehingga mau tidak mau kita harus dapat menampung semua kemungkinan character yang ada.
Untuk kondisi seperti ini mau tidak
mau kita harus menggunakan utf-16 atau utf-8, namun lebih menguntungkan utf-8
karena untuk character alphabet disimpan hanya dalam 1 byte.
Kesimpulan
Character set merupakan sekumpulan karakter yang terstandardisasi.Character set pertama adalah ASCII yang diperkenalkan tahun 1960, sejak itu muncul berbagai character set yang semuanya ditujukan untuk menampung karakter yang dibutuhkan namun terbatas hanya untuk regional tertentu dan tujuan tertentu.
Tahun 1991 mulai diperkenalkan Unicode Standar atau sering disebut Unicode Character Set yang dapat menampung semua karakter yang ada baik yang sudah ada pada character set lain maupun yang belum terdefinisi, dan hingga saat ini Unicode merupakan satu standar yang paling banyak digunakan terutama untuk pertukaran data di internet
B.
IDENTIFIER
Identifier adalah sebuah pengenal atau
pengidentifikasi yang kita deklarasikan agar kompiler dapat mengenalinya. atau
Identifier juga biasa diartikan sebagai nama yang diberikan untuk penamaan
objek, Identifier dapat berupa nama variabel, nama konstanta, nama fungsi, nama
prosedur maupun nama namescape. namu pada kesempatan ini kita akan batasi
pembahasannya pada identifier yang berperan sebagai variabel dan konstanta
saja.
Identifier yang berperan sebagai
variabel dan konstanta berfungsi untuk menampung sebuah nilai yang digunakan
dalam program. Hal ini digunakan untuk memudahkan proses penanganan data atau
nilai, misalnya untuk memasukkan dan menampilkan nilai. Sebagai gambaran
dibawah ini adalah sebuah contoh program yang menggunakan 2 buah identifier
didalamnya.

{kind=link}
Contoh Identifier dalam C++
#include <iostream>
using namespace std;
int main ()
{
char Teks [20]; int X;
cout<<"Masukkan sebuah kata : ";cin>>Teks;
cout<<"Masukkan sebuah angka : ";cin>>X;
cout<<"\nKata yang di masukkan : "<<Teks;
cout<<"\nAngka yang di masukkan : "<<X;
return 0;
}
using namespace std;
int main ()
{
char Teks [20]; int X;
cout<<"Masukkan sebuah kata : ";cin>>Teks;
cout<<"Masukkan sebuah angka : ";cin>>X;
cout<<"\nKata yang di masukkan : "<<Teks;
cout<<"\nAngka yang di masukkan : "<<X;
return 0;
}
Pada program diatas
kita mempunyai 2 buah identifier, yaitu Teks dan X. Pada saat
program dijalankan, identifier tersebut akan digunakan untuk menyimpan nilai
yang dimasukkan dari keyboard. Dalam C++, proses penyimpanan nilai seperti ini
dinyatakan dengan perintah "cin" yang menggunakan operator
">>". Berbeda dengan "cin", perintah "cout"
digunakan untuk menampilkan nilai, dimana operator yang digunakan adalah
operator "<<".
Dalam C++ sendiri dalam pembuatan Identifier kita dapat menuliskannya dengan karakter sebagai berikut:
Dalam C++ sendiri dalam pembuatan Identifier kita dapat menuliskannya dengan karakter sebagai berikut:
- Huruf "a" sampai "z"
- Huruf "A" sampai "Z"
- Bilangan antara "0" sampai "9"
- Underscore " _ "
6 Ketentuan membuat Identifier
Dalam menentukan atau membuat
identifier dalam program, kita harus memperhatikan hal-hal berikut:
1. Case sensitive
Karena bahasa C++ bersifat case
sensitive, maka C++ juga akan membedakan identifier yang ditulis dengan huruf
kapital dan huruf kecil. Misalnya identifier ABC tentunya akan
berbeda dengan identifier aBC.
2. Tidak boleh diawali dengan
Angka
Identifier tidak boleh diawali
dengan karakter yang berupa angka, berikut contohnya:

3. Tidak menggunakan spasi
Identifier tidak boleh mengandung
spasi, biasanya spasi diganti dengan underscore "_" , berikut
contohnya:

4.
Tidak menggunakan karakter simbol
Identifier tidak boleh
menggunakan karakter-karakter simbol (#,$,%,^,!,@,?, dll), berikut contohnya:

5. Tidak menggunakan kata kunci
(keyword)
Identifier tidak boleh
menggunakan kata kunci (keyword) yang terdapat pada C++, berikut contohnya:

6. Sesuaikan penamaan
Nama identifier sebaiknya disesuaikan dengan kebutuhan, artinya jangan sampai orang lain bingung hanya kara kita salah / asal dalam penamaan identifier, contohnya:
Nama identifier sebaiknya disesuaikan dengan kebutuhan, artinya jangan sampai orang lain bingung hanya kara kita salah / asal dalam penamaan identifier, contohnya:

Contoh Identifier sebagai Konstanta dalam C++
Konstanta adalah jenis identifier
yang bersifat konstan atau tetap, artinya nilai dari konstanta didalam program
tidak dapat diubah.berikut Contoh Identifier sebagai Konstanta dalam C++:

{kind=link}

Contoh Identifier sebagai Variabel dalam C++
Berbeda dengan konstanta yang
mempunyai nilai tetap, variabel adalah sebuah identifier yang mempunyai nilai
dinamis. Arti kata "dinamis" disini bermaksud bahwa nilai variabel
tersebut dapat kita ubah sesuai kebutuhan dalam program. berikut Contoh
Identifier sebagai Variabel dalam C++, jangan lupa amati perbedaanya dengan
Identifier sebagai konstanta:

Contoh Identifier sebagai
Variabel dalam C++
|

C.
KEYWORD
Ada beberapa keyword dalam bahasa C, diantaranya:
KEYWORD
|
KETERANGAN
|
Auto
|
Keyword auto digunakan untuk
membuat variabel lokal. Namun demikian keyword ini jarang digunakan
|
Break
|
Digunakan untuk keluar dari fo,
for atau loop while dengan melewati kondisi loop yang normal. Keyword ini
juga digunakan untuk keluar dari perintah switch
|
Switch
|
Perintah switch adalah bagian
dari bebrapa perintah yang daa pada C. Perintah ini digunakan untuk
pembuatan rute satu dengan bebrapa cara yang berbeda. Tiap keberhasilan
perintah dapat berasal dari satu perintah sampai beberapa perintah, panjang
porsi default dapat dipakai. Switch akan bekerja dengan pengontrolan
"control-var" terhadap konstanta. Jika telah diketemukan suatu
keserasian, makan pelaksanaan perintah tersebut berhasil. Jika urutan
perintah yang berhubungan dengan case yang sesuai dengan nilai dari
control-var yang tidak berisi break, maka suatu eksekusi perintah akan
berlanjut ke case selanjutnya, dan akan terus berjalan sampai perintah break
diketemuan atau sampai perintah switch berakhir.
|
Case
|
perintah yang ada dalam perintah
switch untuk membandingkan argumen dan parameter
|
Char
|
Tipe data yang digunakan untuk
membuat karakter variasi
|
Const
|
berasal dari kata
"constant" modifier "const" akan mengatakan pada
compiler bahwa variabel yang mengikuti idak dapat dimodifikasi, namun
demikian saat dideklarasikan variable const dapat diberi nilai awal
|
Continue
|
Digunkan untuk menyediakan porsi
code pada suatu loop dan memaksa "conditional test" untuk
ditampilkan
|
Default
|
digunakan pada perintah switch
yang memberi tanda default blok dari code yang akan dibuat jika tidak ada
kecocokan pada switch
|
Do
|
Merupakan salah satu dari
konstruksi loop yang ada pada C. Jika hanya satu perintah yang diulang, maka
tanda kurung tidak diperlukan. Tanda kurung disini hanya memperjelas suatu
perintah. Loop do adalah satu satunya perintah dalam C yang selalu minimal
satu interasi, sebab suau ondisi akan diuji pada bagian bawah loop. Loop do
biasanya dipakai untuk membaca file disk
|
Double
|
Adalah suatu penentu tipe data
yang digunakan untuk membuat "double-percision" variabel
"floating-point"
|
If
|
Suatu fungsi yang mendeklarasikan
sebuah persyaratan. Jika persyaratan itu tidak terpenuhimaka perintah tidak
akan dijalankan atau menjalankan perintah else
|
Else
|
Suatufungsiyang digunkan sebagai
alternatif dalam fungsi if
|
Enum
|
Digunakan untuk membuat
enumerasi(enumeration). Enumerasi adalah suatu daftar yang sederhana dari
konstanta integer yang diberi nama. Oleh sebab itu, tipe data enum ini
menentukan apa yang dibandingkan dalam daftar tersebut
|
Extern
|
Tipe data modifier yang digunakan
untuk memberitahu compiler bahwa suatu variabel telah dibuat li lai tempat
daam program. Tipe ini sering digunakan pada kata penghubung dengan susunan
file terpisah yang memperlakukan data global yang sama serta digabungkan
bersama. Pada dasarnya extern ini memberitahu compiler tentang tipe variabel
tanpa harus membuat variabel itu sendiri
|
Float
|
Tipe data apecifier yang
digunakan untuk membuat variabel floating-point
|
For
|
Loop yang memungkinkan pemberian
huruf awal dan kenaikan secara otomatis dari variabel counter
|
Goto
|
Akan menyebabkan program melompat
pada lael yang ditentukan dengan perintah goto
|
int
|
Tipe data specifieryang digunakan
untuk membuat variabel integer (bilangn bulat)
|
Long
|
Tipe data modifier yang digunakan
untuk membuat variabel integer menjadi double-length
|
Register
|
Adalah modifier penyimpanan yang
digunakan untuk meminta agar satu pemasukan pada variabel dioptimalkan
kecepatanya. Secara tradisional register hanya dapat digunakan pada variabel
integer dan karakter, register tersebut menyebabkan variabel-variabel
tersebut disimpan dalam register CPU sebagai pengganti dari ditempatkannya
pada memory. Standar ANSIC telah diperluas definisinya agar dapat memasukkan
semua tipe data. Namun demikian data selain integer dan karakter biasanya
tidak dapat disimpan di CPU register. Untuk tipe data yang lain baik berupa
cache memori akan dipakai yang kemudian meminta register untuk disimpan.
Register hanya dapat digunakan pada variabel lokal
|
Retur
|
Perintah return akan memaksa
suatu pengembalian dari fungsi dan dapat digunakan untuk mentransferkembali
suatu angka pada return pemanggilan
|
Short
|
Modifier tiper data yang
digunakan untuk mendeklarasikan integer pendek
|
Signed
|
Tipe modifier signed digunakan
untuk menentukan suatu tipe dana signed-char
|
Sizeof
|
Akan mengembalikan panjang
variabel tipe yang mendahuluinya. Jikan yang mendahului adalah suatu
variabel maka tanda kurung bersifat optional
|
Static
|
Tipe data modifier yang digunakan
untuk menyuruh compiler agar membuat penyimpanan yang permanen untuk
variabel lokal yang mendahuluinya. Hal ini memungkinkan suatu variabel yang
telah ditentukan mempertahankan nilai antara pemanggilan fungsi
|
Struc
|
digunakna untuk membuat variabel
kompleks atau konglomerat, yang disebut :structure", yang terbuat dari
satu elemen tipe data
|
Typedef
|
keyword typedef berguna untuk
membuat alias dari suatu tipe data
|
Union
|
Union digunakan untuk menunjukkan
dua variabel atau lebih pada lokasi memori yang sama.
|
Unsigned
|
"unsigned" adalah tipe
data modifier yang memerintahkan compiler untul< menghapus tanda bit dari
suatu integer dan menggunakan seluruh bit untuk keperluar arithmetic. Hal
semacam ini menyebabkan ukuran integer terbesar menjadi dobel tapi hanya
terbatas pada angka-angka positif saja.
|
Void
|
Tipe specifier "void"
pada pokoknya digunakan untuk secara jelas mendeklarasikan fungsi yang tidak
mengembalikan suatu nilai (dalam arti penuh), tipe ini juga digunakan untuk
membuat pointer "void" (pointer pada "void"), yaitu
pointer generic yang dapat menunjukkan beberapa tipe object.
|
Volatile
|
Modifier "volatile"
digunakan untuk memberitahu Compiler bahwa suatu variabel mungkin telah
mempunyai suatu isi yang telah dipilih dengan cara yang tidak ditentukan
oleh suatu program. Contoh, variabel-variabel yang diubah dengan hardware
seperti "realtime clock", 'Interrupt" atau input-input yang
lain, harus dinyatakan sebagai volatile
|
While
|
Adalah suatu loop. Jika suatu
perintah tunggal adalah object dari "while", maka tanda kurung
dapat dihilangkan, "while" akan menguji kondisinya pada bagian
atas suatu loop. Oleh sebab itu jika kondisinya salah untuk memulai,maka
loop tidak akan berjalan, meskipun hanya sekali. Kondisi tersebut mungkin
dapat berupa suatu ekspresi.
|
D. TIPE DATA
Jenis-jenis Tipe Data dalam Bahasa C
Terdapat 8 tipe data di dalam bahasa pemrograman C yang bisa dibagi ke dalam 4 kelompok besar: tipe data dasar, tipe data turunan, tipe data bentukan, dan tipe data void.1. Tipe Data Dasar
Sesuai dengan namanya, tipe data dasar adalah tipe data paling dasar yang tersedia di dalam bahasa pemrograman C. Terdapat 3 jenis tipe data dasar:
- Char: tipe data yang berisi 1 huruf atau 1 karakter.
- Integer: tipe data untuk menampung angka bulat.
- Float: tipe data untuk menampung angka pecahan.
2. Tipe Data Turunan
Tipe data turunan berasal dari tipe data dasar yang dikelompokkan atau di modifikasi. Terdapat 3 tipe data turunan di dalam bahasa pemrograman C:
- Array: Tipe data yang terdiri dari kumpulan tipe data dasar. Tipe data tersebut harus 1 jenis.
- Structure: Tipe data yang terdiri dari kumpulan tipe data dasar. Tipe data tersebut bisa lebih dari 1 jenis.
- Pointer: Tipe data untuk mengakses alamat memory secara langsung.
3. Tipe Data Bentukan (enum)
Sesuai dengan namanya, tipe data bentukan adalah tipe data yang dibuat sendiri oleh kita (programmer). Isinya berupa data-data yang sudah ditentukan. Tipe data bentukan ini dikenal juga sebagai Enumerated Data Type atau disingkat sebagai enum.
4. Tipe Data Void
Tipe data void adalah tipe data khusus yang menyatakan tidak ada data. Penggunaannya khusus untuk beberapa situasi seperti function yang tidak mengembalikan nilai (return void), atau mengisi argumen function dengan nilai kosong.
- Char
- Integer
- Float
- Array
- Structure
- Pointer
- Enum
- Void
Bahasa C memang tidak memiliki tipe boolean bawaan, tapi bisa diakali dengan membuatnya menggunakan tipe data bentukan (enum), atau menggunakan library khusus: stdbool.h.
Sedangkan untuk string, di dalam bahasa C termasuk ke dalam array. String di defenisikan sebagai array dari tipe data char.
E.
KONSTANTA
Mengenal Konstanta pada C
Konstanta adalah sebuah nilai tetapan.Bisa juga dibilang sebagai variabel yang tidak bisa diubah nilainya.
Ada dua cara pembuatan konstanta pada C:
- Menggunakan
#define; - dan Menggunakan
const.
define:#include<stdio.h>
#define SEPULUH 10 #define VERSI 4.5 #define JENIS_KELAMIN 'L' voidmain(){
printf("isi konstanta SEPULUH adalah %i\n", SEPULUH);
printf("isi konstanta VERSI adalah %f\n", VERSI);
printf("isi konstanta JENIS_KELAMIN adalah %i\n", JENIS_KELAMIN);
}isi konstanta SEPULUH adalah10
isi konstanta VERSI adalah 4.500000Contoh menggunakanisi konstanta JENIS_KELAMIN adalah76
const:#include<stdio.h>
voidmain(){
constdoublePI=3.14;
constJENIS_KELAMIN='P';
constVERSI=11;
printf("isi konstanta PI adalah %f\n", PI);
printf("isi konstanta JENIS_KELAMIN adalah %i\n", JENIS_KELAMIN);
printf("isi konstanta VERSI adalah %f\n", VERSI);
}isi konstanta PI adalah 3.140000isi konstanta JENIS_KELAMIN adalah80
isi konstanta VERSI adalah 3.140000#define dan const
terletak pada format penulisannya.Pada
#define kita tidak
perlu menuliskan tipe data, sedangkan const
harus.Pada
#define kita tidak
membutuhkan titik koma di akhir, sedangkan pada const kita harus menuliskan titik koma.Posisi penulisan untuk
#define
dan const bisa ditulis di
dalam main() maupun di luar.Oh iya, untuk nama konstanta disarankan menggunakan huruf kapital untuk menandakan itu sebuah konstanta.
Apa yang akan terjadi jika saya mencoba mengisi nilai ke dalam konstanta?
Ya programnya akan error.

F.
VARIABEL DAN ARRAY
Variable Array adalah
kumpulan dari beberapa nilai yang mempunyai tipe yang sama. Misalkan interger semua,
float semua dan sebagainya. Untuk membedakan antara nilai satu dengan
lainnya digunakan suatu subscript yang sering disebut index. Suatu varriabel
array dapat digunakan untuk menyimpan beberapa nilai dengan tipe sama.
Contohnya variable bilangan[n]. Maka dapat menyimpan beberapa nilai dengan
index mulai dari 0 sampai n-1 yaitu bilangan[0]. Bilangan[1]….. bilangan[n-1].
Nilai subscript dapat berupa konstansta variable dan ekspresi interger.
·
Membuat program untuk
mengurutkan data dengan urutan naik yang dimasukkan melalui keyboard.
Masukkan program
#include <stdio.h>
#include <math.h>
main()
{int data,a,z,b;
printf(“Masukan jumlah data = “);
scanf(“%d”,&data);
int
nilai[data];
for(a=0;a<data;a++){
printf(“data ke %d = “,a+1);
scanf(“%d”,&nilai[a]);
}
for(a=0;a<data;a++){
for(b=a+1;b<data;b++){
if(nilai[a]<nilai[b]){
z=nilai[b];
nilai[b]=nilai[a];
nilai[a]=z;
}}}
printf(“Data urutannya dari terbesar adalah “);
for(a=0;a<data;a++){
printf(“%d”,nilai[a]);
if(a<data-1){printf(“,”);}
}}
Lalu menunjukkan hasil
seperti pada gambar
- Google+

G.
DECLARASI
Deklarasi
(Declare) sangat diperlukan oleh kita jika kita ingin menggunakan pengenal atau
biasa disebut identifier dalam sebuah kode program yang akan kita buat.
Deklarasi di bagi jadi 3 yaitu :
Deklarasi di bagi jadi 3 yaitu :
1.Deklarasi variabel
Bentuk umum sebuah pendeklarasian suatu variable adalah :
{kind=link}
2.Deklarasi Konstanta
Di dalam penggunaan konstanta di
bahasa pemrograman C dideklarasikan menggunakan preprocessor #define.
Contohnya:
#define PHI 3.14
#define nom “141206”
#define nama “hakkun”
#define kelas “MM-3”
#define PHI 3.14
#define nom “141206”
#define nama “hakkun”
#define kelas “MM-3”
3.Deklarasi Fungsi
Fungsi
adalah bagian yang terpisah dari sebuah program yang kita buat dan dapat
diaktifkan atau dipanggil di manapun di dalam program. Fungsi dalam sebuah
bahasa pemrograman C ada yang sudah disediakan sebagai fungsi pustaka seperti
printf(), scanf(), getch() dan untuk menggunakannya tidak perlu dideklarasikan.
Fungsi yang perlu dideklarasikan terlebih dahulu adalah fungsi yang dibuat oleh
kita. Bentuk umum deklarasi sebuah fungsi adalah :
Tipe_fungsi nama_fungsi(parameter_fungsi);
Contohnya :
float luas_lingkaran(int jari);
void tampil();
int tambah(int x, int y);
Tipe_fungsi nama_fungsi(parameter_fungsi);
Contohnya :
float luas_lingkaran(int jari);
void tampil();
int tambah(int x, int y);
H.
EXPRESSION
Ekspresi
adalah transformasi nilai menjadi keluaran yang dilakukan melalui suatu
perhitungan (komputasi). Ekspresi terdiri atas operand dan operator, contoh
ekspresi: “a + b”. Untuk pebuah a dan b dinamakan operand, sedangkan “+”
merupakan operator.
Dalam algoritma pemograman terdapat 3 macam ekspresi :
1. Ekspresi Aritmetik
Ekspresi Aritmetik adalah ekspresi yang baik operandnya bertipe numerik dan hasilnya juga bertipe numerik.
Dalam algoritma pemograman terdapat 3 macam ekspresi :
1. Ekspresi Aritmetik
Ekspresi Aritmetik adalah ekspresi yang baik operandnya bertipe numerik dan hasilnya juga bertipe numerik.
Contoh 1.
DEKLARASI
a, b, c : real
i, j, k : integer
ALGORITMA
a * b = c
i + j = k
a, b, c : real
i, j, k : integer
ALGORITMA
a * b = c
i + j = k
Keterangan. Operator yang mempunyai tingkatan lebih tinggi
lebih dahulu dikerjakan daripada operator yang tingkatannya lebih rendah.
Contoh : a/c + b. Yang pertama dikerjakan adalah a/c, kemudian hasilnya
ditambahkan dengan b.
Tingkatan operator aritmetika (dari tertinggi ke terendah) :
(i). /, div, mod
(ii) *
(iii) +, –
(i). /, div, mod
(ii) *
(iii) +, –
Pada ekspresi aritmetik terdapat 2 buah operator yaitu :
– Operator biner, yaitu ekspresi yang operatornya membutuhkan 2 buah operand. Contoh a + b
– Operator Uner, yaitu “-” atau operator yang punya 1 operand contoh “-2”
– Operator biner, yaitu ekspresi yang operatornya membutuhkan 2 buah operand. Contoh a + b
– Operator Uner, yaitu “-” atau operator yang punya 1 operand contoh “-2”
Contoh 2. (Penulisan ekspresi dengan notasi algoritma)
T = 5/9 * (c + 32)
Z = (2*x + y) / (5 * w)
Y = 5((a+b) / (c*d) + m (p + q))
T = 5/9 * (c + 32)
Z = (2*x + y) / (5 * w)
Y = 5((a+b) / (c*d) + m (p + q))
2. Ekspresi Relasional
Ekspresi relasional adalah ekspresi dengan operator <, ≤, >, ≥, =, dan ≠, not, and, or dan xor dengan menghasilkan nilai bertipe boolean (true atau false). Biasanya ekspresi Relasional disebut ekspresi boolean.
Ekspresi relasional adalah ekspresi dengan operator <, ≤, >, ≥, =, dan ≠, not, and, or dan xor dengan menghasilkan nilai bertipe boolean (true atau false). Biasanya ekspresi Relasional disebut ekspresi boolean.
Contoh
DEKLARASI
const ketemu = false
const ada = true
const X = 8
const Y = 12
ALGORITMA
not ada = false
ada or ketemu = true
ada and true = true
X < 5 = false
ada or (X = Y) = true
const ketemu = false
const ada = true
const X = 8
const Y = 12
ALGORITMA
not ada = false
ada or ketemu = true
ada and true = true
X < 5 = false
ada or (X = Y) = true
3. Ekspresi String
Ekspresi String adalah ekspresi dengan operator “+” (operator penyambungan / concatenation).
Ekspresi String adalah ekspresi dengan operator “+” (operator penyambungan / concatenation).
Contoh
DEKLARASI
Kar : char
S : string
{ Contoh-contoh ekspresi untuk tipe string}
(S + Kar) + ‘ C ’
‘Jl.Ganesha’ + ‘No.10’
Kar : char
S : string
{ Contoh-contoh ekspresi untuk tipe string}
(S + Kar) + ‘ C ’
‘Jl.Ganesha’ + ‘No.10’
Menuliskan Nilai ke Piranti Keluaran
Nilai yang disimpan dimemori dapat ditampilkan ke piranti
keluaran (output) dengan instruksi penulisan menggunakan notasi “write”.
write (var1, var2, var3, …, varN)
write (konstanta)
write (ekspresi)
write (nama, konstanta, ekspresi)
write (var1, var2, var3, …, varN)
write (konstanta)
write (ekspresi)
write (nama, konstanta, ekspresi)
Contoh:
DEKLARASI
A,B : integer
NRP : integer
nama_mhs : string
nilai : real
type Jam : record < hh : integer, mm : intege, ss : integer >
J : Jam
ALGORITMA
A <– 8
B <– 6
nama_mhs <– “Andi Baco”
NRP <– 10290056
nilai <– 90.8
J.hh <– 6
J.mm <– 12
J.ss <– 45write (100)
write (A)
write (‘A’)
write (‘Jurusan Teknik Informatika ITB’)
write (‘Nilai A = ’, A)
write (nama_mhs, NRP, nilai)
write (A+B)
write (‘Nilai seluruhnya adalah’, A + B / 2 * 10)
write (J.hh, ‘:’, J.mm, ‘:’, J.ss)
A,B : integer
NRP : integer
nama_mhs : string
nilai : real
type Jam : record < hh : integer, mm : intege, ss : integer >
J : Jam
ALGORITMA
A <– 8
B <– 6
nama_mhs <– “Andi Baco”
NRP <– 10290056
nilai <– 90.8
J.hh <– 6
J.mm <– 12
J.ss <– 45write (100)
write (A)
write (‘A’)
write (‘Jurusan Teknik Informatika ITB’)
write (‘Nilai A = ’, A)
write (nama_mhs, NRP, nilai)
write (A+B)
write (‘Nilai seluruhnya adalah’, A + B / 2 * 10)
write (J.hh, ‘:’, J.mm, ‘:’, J.ss)
I.
Hasil dari Algoritma diatas :
100
8
A
Jurusan Teknik Informatika ITB
Nilai A = 8
Andi Baco, 10290056, 90.8
14
Nilai seluruhnya adalah 70
6 : 12 : 45
100
8
A
Jurusan Teknik Informatika ITB
Nilai A = 8
Andi Baco, 10290056, 90.8
14
Nilai seluruhnya adalah 70
6 : 12 : 45
Berikut adalah contoh-contoh Algoritma dengan menggunakan
teknik pseude-code kemudian ditranslasi ke bahasa pemograman Pascal dan C.
ALGORITMIK:
DEKLARASI
type Titik : record
P : Titik
a,b : integer
nama_arsip, h : string
nilai : real
c : char
ALGORITMA
nilai <– 1200.0
read (P.x, P.y)
read (nama_arsip)
h <– nama_arsip
read (a, b)
read (c)
write (‘Nama Arsip : ’, nama_arsip)
write (‘Koordinat titik adalah :’, P.x, ‘,’, P.y)
write (b, nilai)
write (‘Karakter yang dibaca adalah ’, C )
type Titik : record
P : Titik
a,b : integer
nama_arsip, h : string
nilai : real
c : char
ALGORITMA
nilai <– 1200.0
read (P.x, P.y)
read (nama_arsip)
h <– nama_arsip
read (a, b)
read (c)
write (‘Nama Arsip : ’, nama_arsip)
write (‘Koordinat titik adalah :’, P.x, ‘,’, P.y)
write (b, nilai)
write (‘Karakter yang dibaca adalah ’, C )
J.
STATEMENT
Statement
adalah unsur dasar pembentuk program. Suatu program terdiri dari beberapa
statement dimana komputer akan melakukan tugas tertentu sesuai dengan urutan
statement. Statement ada tiga jenis, yaitu : expression statement, compound
statement, control statement.
Expression
statement adalah suatu expression yang diikuti dengan tanda titik koma (;).
Compound statement adalah adalah dua atau lebih statement yang
dikelompokkan menjadi satu dengan cara memberi batas tanda kurung awal dan
tanda kurung akhir, sehingga tidak perlu diakhiri dengan tanda titik koma pada
akhir dari compound. Control statement adalah statement yang
mengendalikan langkah-langkah program, contohnya for loop, while loop, dan if-else.
Tipe
statemen di Java:
Statement pendeklarasian – statemen
inimeng-create variabel yang dapat digunakan untuk menyimpan data. Contoh:
int i;
String s = "Ini adalah
string";
Pelanggan p = new Pelanggan();
Statement ekspresi – untuk melakukan
kalkulasi. Contoh:
i = a + b;
pajakPenjulalan = totalHarga *
pajakNilai;
System.out.println("Hello,World!");
Statement kontrol, misalnya statemen
if, for, do, while, switch.
K.
SYMBOLIC CONTACT
Symbolic Constant adalah suatu nama
dimana digunakan untuk menggantikan suatu nilai tertentu , sehingga akan lebih
mudah dalam pembacaan suatu program, contohnya #define PI 3,14. PI ditulis
huruf besar untuk membedakan dengan variabel lain.
L.
OPERATOR
Operator Operator Pada Bahasa C
adalah simbol atau karakter yang digunakan oleh program untuk melakukan sebuah
operasi dalam sebuah proses program seperti operasi bilangan dan operasi
string. Bahasa C mengenal penggunaan beberapa operator dengan fungsi yang
berbeda-beda. Setiap operator
memiliki kedudukan atau hirarki saat penanganan
program. Operator dengan hirarki lebih tinggi akan dikerjakan lebih dahulu
dibandingkan operator dengan hirarki lebih rendah.
Operator Operator Pada Bahasa C
Berikut ini operator operator pada bahasa C dan penjelasannya yang sering digunakan pada pemrograman mikrokontroler AVR :1. Operator Aritmatika
Adalah operator yang digunakan untuk operasi bilangan seperti penjumlahan, pengurangan, perkalian, pembagian, modulus, increment dan decrement. Operator aritmatika bisa digunakan pada semua tipe bilangan seperti char, int, long int dan float. Operator aritmatika juga bisa menangani tipe signed dan unsigned.Increment adalah operasi bilangan dimana bilangan hasil merupakan bilangan asal ditambah satu, sedangkan decrement adalah operasi bilangan dimana bilangan hasil merupakan bilangan asal dikurang satu.
Berikut ini beberapa operator aritmatika pada bahasa C :
Operator
|
Nama
|
Contoh
|
Hasil
|
+
|
Penjumlahan
|
z = x + y
|
Penjumlahan
dari x dan y
|
–
|
Pengurangan
|
z = x – y
|
Selisih dari
x dan y
|
*
|
Perkalian
|
z = x * y
|
Perkalian
dari x dan y
|
/
|
Pembagian
|
z = x / y
|
Pembagian x
oleh y
|
%
|
Modulus
|
z = x % y
|
Sisa dari x
dibagi y
|
++
|
Increment
|
x++
|
Sama dengan
x = x+1
|
—
|
Decrement
|
x–
|
Sama dengan
x = x-1
|
2. Operator Bitwise
Adalah operator yang menangani operasi bilangan biner seperti and, or, not dan sebagainya. Operator bitwise ini akan menangani data sesuai dengan tipenya. Misalnya sebuah data bertipe char atau byte maka bilangan yang dihasilkan adalah sebesar 8 bit.Berikut ini beberapa operator bitwise pada bahasa C :
Operator
|
Nama
|
Contoh
|
Dalam
biner (4bit)
|
Hasil
Biner
|
Hasil
Decimal
|
&
|
AND
|
x = 5 &
1
|
0101 &
0001
|
0001
|
1
|
|
|
OR
|
x = 5 | 1
|
0101 | 0001
|
0101
|
5
|
~
|
NOT
|
x = ~ 5
|
~0101
|
1010
|
10
|
^
|
XOR
|
x = 5 ^ 1
|
0101 ^ 0001
|
0100
|
4
|
<<
|
Left shift
|
x = 5
<< 1
|
0101
<< 1
|
1010
|
10
|
>>
|
Right shift
|
x = 5
>> 1
|
0101
>> 1
|
0010
|
2
|
3. Operator Penugasan
Adalah operator yang digunakan untuk memberi nilai pada sebuah variabel. Operator penugasan yang paling dasar adalah sama dengan (=). Dari operator ini dapat dikembangkan beberapa operator penugasan lain seperti +=, -= dan sebagainya.Berikut ini beberapa operator penugasan pada bahasa C :
Operator
|
Penugasan
|
Sama
dengan
|
Deskripsi
|
=
|
x = y
|
x = y
|
variabel x
memperoleh nilai dari variabel y
|
+=
|
x += y
|
x = x + y
|
variabel x
memperoleh nilai dari x + y
|
-=
|
x -= y
|
x = x – y
|
variabel x
memperoleh nilai dari x – y
|
*=
|
x *= y
|
x = x * y
|
variabel x
memperoleh nilai dari x * y
|
/=
|
x /= y
|
x = x / y
|
variabel x
memperoleh nilai dari x / y
|
%=
|
x %= y
|
x = x % y
|
variabel x
memperoleh nilai dari x % y
|
<<=
|
x <<=
y
|
x = x
<< y
|
variabel x
memperoleh nilai dari x << y
|
>>=
|
x >>=
y
|
x = x
>> y
|
variabel x
memperoleh nilai dari x >> y
|
&=
|
x &= y
|
x = x &
y
|
variabel x
memperoleh nilai dari x & y
|
|=
|
x |= y
|
x = x | y
|
variabel x
memperoleh nilai dari x | y
|
^=
|
x ^= y
|
x = x ^ y
|
variabel x
memperoleh nilai dari x ^ y
|
4. Operator Perbandingan
Adalah operator yang digunakan untuk membandingkan dua buah nilai atau variabel. Nilai yang dibandingkan bisa berupa angka maupun string. Hasil dari perbandingan ini berupa nilai boolean, yaitu true (benar) atau false (salah).Berikut ini beberapa operator perbandingan pada bahasa C :
Operator
|
Nama
|
Contoh
|
Hasil
|
==
|
Sama dengan
|
a == b
|
benar jika a
sama dengan b
|
!=
|
Tidak sama
dengan
|
a != b
|
benar jika a
berbeda dengan b
|
>
|
Lebih besar
|
a > b
|
benar jika a
lebih besar dari b
|
<
|
Lebih kecil
|
a < b
|
benar jika a
lebih kecil dari b
|
>=
|
Lebih besar
atau sama dengan
|
a >= b
|
benar jika a
lebih besar atau sama dengan b
|
<=
|
Lebih kecil
atau sama dengan
|
a <= b
|
benar jika a
lebih kecil atau sama dengan b
|
5. Operator Logika
Adalah operator yang digunakan untuk menangani tipe data boolean. Nilai data boolean bisa berupa kondisi benar (true) atau salah (false) dan bisa juga 1 atau 0.Berikut ini beberapa operator logika pada bahasa C :
Operator
|
Nama
|
Contoh
|
Hasil
|
&&
|
And
|
a &&
b
|
benar jika a
and b bernilai benar
|
||
|
Or
|
a || b
|
benar jika
salah satu a atau b bernilai benar
|
!
|
Not
|
!a
|
benar jika a
tidak benar
|
6. Operator Lain
Selain dari beberapa operator diatas, ada beberapa operator lain yang juga sering dipakai terutam pada pemrograman array misalnya operator sizeof dan ppointer (*).
Operator
|
Keterangan
|
Contoh
|
Hasil
|
sizeof()
|
Menghasilkan
ukuran (size) dari variabel.
|
sizeof(a)
|
Menghasilkan
bilangan integer, misal 5
|
&
|
Mengembalikan
alamat (address) dari variabel.
|
&a
|
Menghasilkan
alamat sebenarnya dari variabel
|
*
|
Pointer ke
sebuah variabel.
|
*a
|
Mengarahkan
pointer ke sebuah variabel.
|
? :
|
Operator
kondisi
|
b = (a == 1)
? 20: 30;
|
Jika kondisi
a==1 benar maka nilai b=20 dan jika salah maka nilai b=30
|
INPUT DAN OUTPUT DASAR
a)
FUNGSI KARAKTER
Operasi
Karakter
Fungsi-fungsi pustaka untuk opersai karakter berada pada file judul ctype.h.
a. Menyeleksi Status Karakter
Fungsi-fungsi pustaka atau mako yang dapat digunakan adalah :
Makro-makro ini akan menghasilkan nilai benar (True) jika nilai karakter yang diseleksi termasuk dalam status kelompoknya.
Contoh1 :
#include<stdio.h>
#include<conio.h> //file header untuk fungsi getche()
#include<ctype.h> //file header untuk fungsi isspace(c)
#define lagi 1
main() {
int karakter;
do { karakter = getche(); // menerima input data karakter tanpa enter
if(isspace(karakter)) break; } /*bila yg diinput berupa spasi, backspace, tab atau enter maka keluar dari proses looping*/
while(lagi); /*looping dilakukan selama menerima input*/ }
Contoh2 :
#include<stdio.h>
#include<conio.h>
#include<ctype.h>
main() { int input;
input = getche(); //input tanpa penekanan enter
if(isalpha(input)) printf(“ adalah huruf\n”);
else printf(“ bukan huruf\n”);
}
output :
d adalah huruf
1 bukan huruf
ket : if(isalpha(input)) printf(“adalah huruf\n”); artinya bila input benar berisi karakter huruf maka akan dicetak adalah huruf dan bila tidak akan mencetak bukan huruf.
b. Mengkonversi Nilai Karakter
fungsi :
tolower() : merubah karakter huruf besar menjadi huruf kecil
toupper() : merubah karakter huruf kecil menjadi besar
Contoh :
#include<stdio.h>
#include<conio.h>
#include<ctype.h>
main() { char kata = „A‟,jawab;
do { printf(“%c %c\n”, tolower(kata),toupper(„b‟));
printf(“Mau coba lagi : “);
jawab = getchar(); }
while(toupper(jawab) = = „Y‟ ); }
Ouput :
a B
Mau coba lagi : y
a B
Mau coba lagi : t
Ket : program diatas akan mencetak A menjadi huruf kecil dan B menjadi huruf besar. Perintah while(toupper(jawab) ==‟Y‟) berarti looping akan dilakukan selama jawab = „Y‟ atau „y‟ karena toupper(„y‟) = „Y‟.
Fungsi-fungsi pustaka untuk opersai karakter berada pada file judul ctype.h.
a. Menyeleksi Status Karakter
Fungsi-fungsi pustaka atau mako yang dapat digunakan adalah :
Makro-makro ini akan menghasilkan nilai benar (True) jika nilai karakter yang diseleksi termasuk dalam status kelompoknya.
Contoh1 :
#include<stdio.h>
#include<conio.h> //file header untuk fungsi getche()
#include<ctype.h> //file header untuk fungsi isspace(c)
#define lagi 1
main() {
int karakter;
do { karakter = getche(); // menerima input data karakter tanpa enter
if(isspace(karakter)) break; } /*bila yg diinput berupa spasi, backspace, tab atau enter maka keluar dari proses looping*/
while(lagi); /*looping dilakukan selama menerima input*/ }
Contoh2 :
#include<stdio.h>
#include<conio.h>
#include<ctype.h>
main() { int input;
input = getche(); //input tanpa penekanan enter
if(isalpha(input)) printf(“ adalah huruf\n”);
else printf(“ bukan huruf\n”);
}
output :
d adalah huruf
1 bukan huruf
ket : if(isalpha(input)) printf(“adalah huruf\n”); artinya bila input benar berisi karakter huruf maka akan dicetak adalah huruf dan bila tidak akan mencetak bukan huruf.
b. Mengkonversi Nilai Karakter
fungsi :
tolower() : merubah karakter huruf besar menjadi huruf kecil
toupper() : merubah karakter huruf kecil menjadi besar
Contoh :
#include<stdio.h>
#include<conio.h>
#include<ctype.h>
main() { char kata = „A‟,jawab;
do { printf(“%c %c\n”, tolower(kata),toupper(„b‟));
printf(“Mau coba lagi : “);
jawab = getchar(); }
while(toupper(jawab) = = „Y‟ ); }
Ouput :
a B
Mau coba lagi : y
a B
Mau coba lagi : t
Ket : program diatas akan mencetak A menjadi huruf kecil dan B menjadi huruf besar. Perintah while(toupper(jawab) ==‟Y‟) berarti looping akan dilakukan selama jawab = „Y‟ atau „y‟ karena toupper(„y‟) = „Y‟.
b)
FUNGSI PRINT DAN SCANF
Printf merupakan sebuah fungsi dalam
file header <stdio. h>. Printf digunakan untuk membuat sebuah output
berupa tampilan. contoh:
#include <stdio.h>
void main()
{
printf (” ILC DONK “) ;
}
kata yang akan di tampilkan di ketik
di antara tanda (” “). dan dalam setiap statement harus di akhiri dengan tanda”
; “.
selanjutnya kita bahas tentang
scanf.
scanf merupakan sebuah fungsi dalam
file header <stdio.h> juga yang berfungsi untuk menerima inputan dari
user. Untuk belajar tentang scanf kita pelajari dulu tentang variabel. Variabel
di ibaratkan sebuah wadah untuk menampung sebuah nilai maupun karakter dari
inputan user ataupun sudah di tentukan dari awal. Ada banyak macam tipe
variabel
- int -> untuk menampung nilai
- char -> untuk menampung karakter
- dll
untuk inisialisasi awal sebuah
variabel dapat di ketik <tipe variabel><spasi><nama
variabel>, contoh char nama;
ini berarti kita membuat variabel
nama bertipe karakter
simak contoh berikut ini
#include <stdio.h>
void main()
{
char nama[10];
{
char nama[10];
printf(“Masukkan nama:”);
scanf(“%s”,&nama);
printf(“\n\n%s\n”,&nama);
}
scanf(“%s”,&nama);
printf(“\n\n%s\n”,&nama);
}
c)
FUNGSI STRING
Operasi String
Suatu string merupakan array dari karakter. Nilai suatu string ditulis dengan tanda petik dua. Suatu nilai string disimpan di memory dengan diakhiri oleh nilai „\0‟ (null). “ABC” disimpan menjadi A B C „\0‟
Inisialisasi
String : char kota[ ] = {„C‟,‟o‟,‟r‟,‟v‟,‟a‟,‟l‟,‟l‟,‟i‟,‟s‟,‟\0‟};
char kota[10] = “Corvallis” ;
char kota[ ] = “Corvallis” ;
Konstanta string, sebagaimana halnya nama array, diperlakukan oleh kompiler sebagai sebuah pointer. Maka pernyataan berikut sama dengan inisialisasi di atas.
char *kota = “CORVALLIS”;
perintah : printf(“%s, %c%c”, kota, kota[1],kota[2]); Output : CORVALIS, OR
%s kode format untuk kota berarti mencetak CORVALLIS. %c, kota[1] berarti mencetak elemen array ke-1 dari kota yaitu „O‟, %c,kota[2] berarti mencetak elemen array ke-2 dari kota yaitu „R‟.
Seperti halnya Array, String bila tidak diberi nilai awal maka ukuran karakter harus ditulis, Misal : char Nama[20];
Atau boleh ditulis sebagai pointer :
char *Nama ;
Fungsi2 standar string terdapat pada file judul string.h
1. Menyalin string
Fungsi : strcpy()
Bentuk : srtcpy(string1,string2). Nilai string2 akan dicopy ke string1.
Contoh : strcpy(kota, “satu”) maka string satu akan dicopy ke variable kota.
2. Menghitung panjang string
Fungsi : strlen()
Contoh : strlen(“Corvallis”) maka akan dihasilkan nilai 9
3. menggabungkan string
fungsi : strcat(string1,string2). Nilai string1 akan digabung dengan string2 dan disimpan didalam string1.
Contoh :
char kota[]=”satu”;
strcat(kota, “dua”) maka kota[ ] = “satudua”
4. Mencari Nilai karakter di string
Fungsi : strchr()
Contoh :
char String[ ] =”Abcde”; char *hasil ;
Hasil = strch(String, „B‟); printf(“%s”, hasil);
Maka Hasil akan bernilai “Bcde”
5. Membandingkan dua nilai string
Fungsi : strcmp()
Membandingkan dua nilai string akan menghasilkan nilai integer berupa :
- > 0 bila sring pertama lebih kecil daripada string kedua
- 0 bila string pertama = string kedua
- < 0 bila string pertama lebih besar dari string kedua
Contoh program :
#include <stdio.h>
#include “string.h”
int main( ) {
char kata1[ ] = “Ibu Kota”, *kata2 = “ Jakarta”, data1[ ] ={„A‟,‟B‟,‟c‟,‟d‟,‟\0‟};
char data2[ ] = “ABCD”,*baru ; int hasil;
printf(“panjang string kata1 : %d \n”,strlen(kata1); //menghitung panjang “Ibu Kota”
strcat(kata1,kata2); //mengabung kata1&kata2 disimpan di kata1
printf(“nilai string kata1 setelah operasi : %s \n”,kata1);
strcpy(kata2,data1); //mencopy string data1 disimpan di kata2
printf(“nilai string kata2 setelah operasi : %s \n”,kata2);
hasil = strcmp(data1,data2); //membandingkan data1 dan data2
if (hasil = = 0) printf(“Data1 sama dengan data2”)
else if(hasil< 0) printf(“Data1 lebih kecil dari data2”);
else printf(“Data1 lebih besar dari data2”);
baru = strchr(data2,’C’); //mencari karakter‟C‟ pada data2, hasil disimpan di baru
printf(“\nHasil mencari karakter C : %s”, baru);
return 0; //nilai balik ke fungsi main
}
Output :
panjang string kata1 : 8
Nilai string kata1 setelah operasi : Ibu Kota Jakarta
Nilai string kata2 setelah operasi : ABcd
Data1 lebih besar dari data2
Hasil mencari karakter C : CD
Nilai yang tersimpan pada tiap variabl setelah operasi :
kata1= “Ibu Kota Jakarta” karena menyimpan hasil operasi strcat(kata1,kata2).
kata2 = “Abcd” karena menyimpan hasil opersi strcpy(kata2,data1)
data1 = “Abcd”
data2 = “ABCD”
hasil = lebih besar dari nol karena karakter „c‟ lebih besar dari „C‟
baru = “CD”
Suatu string merupakan array dari karakter. Nilai suatu string ditulis dengan tanda petik dua. Suatu nilai string disimpan di memory dengan diakhiri oleh nilai „\0‟ (null). “ABC” disimpan menjadi A B C „\0‟
Inisialisasi
String : char kota[ ] = {„C‟,‟o‟,‟r‟,‟v‟,‟a‟,‟l‟,‟l‟,‟i‟,‟s‟,‟\0‟};
char kota[10] = “Corvallis” ;
char kota[ ] = “Corvallis” ;
Konstanta string, sebagaimana halnya nama array, diperlakukan oleh kompiler sebagai sebuah pointer. Maka pernyataan berikut sama dengan inisialisasi di atas.
char *kota = “CORVALLIS”;
perintah : printf(“%s, %c%c”, kota, kota[1],kota[2]); Output : CORVALIS, OR
%s kode format untuk kota berarti mencetak CORVALLIS. %c, kota[1] berarti mencetak elemen array ke-1 dari kota yaitu „O‟, %c,kota[2] berarti mencetak elemen array ke-2 dari kota yaitu „R‟.
Seperti halnya Array, String bila tidak diberi nilai awal maka ukuran karakter harus ditulis, Misal : char Nama[20];
Atau boleh ditulis sebagai pointer :
char *Nama ;
Fungsi2 standar string terdapat pada file judul string.h
1. Menyalin string
Fungsi : strcpy()
Bentuk : srtcpy(string1,string2). Nilai string2 akan dicopy ke string1.
Contoh : strcpy(kota, “satu”) maka string satu akan dicopy ke variable kota.
2. Menghitung panjang string
Fungsi : strlen()
Contoh : strlen(“Corvallis”) maka akan dihasilkan nilai 9
3. menggabungkan string
fungsi : strcat(string1,string2). Nilai string1 akan digabung dengan string2 dan disimpan didalam string1.
Contoh :
char kota[]=”satu”;
strcat(kota, “dua”) maka kota[ ] = “satudua”
4. Mencari Nilai karakter di string
Fungsi : strchr()
Contoh :
char String[ ] =”Abcde”; char *hasil ;
Hasil = strch(String, „B‟); printf(“%s”, hasil);
Maka Hasil akan bernilai “Bcde”
5. Membandingkan dua nilai string
Fungsi : strcmp()
Membandingkan dua nilai string akan menghasilkan nilai integer berupa :
- > 0 bila sring pertama lebih kecil daripada string kedua
- 0 bila string pertama = string kedua
- < 0 bila string pertama lebih besar dari string kedua
Contoh program :
#include <stdio.h>
#include “string.h”
int main( ) {
char kata1[ ] = “Ibu Kota”, *kata2 = “ Jakarta”, data1[ ] ={„A‟,‟B‟,‟c‟,‟d‟,‟\0‟};
char data2[ ] = “ABCD”,*baru ; int hasil;
printf(“panjang string kata1 : %d \n”,strlen(kata1); //menghitung panjang “Ibu Kota”
strcat(kata1,kata2); //mengabung kata1&kata2 disimpan di kata1
printf(“nilai string kata1 setelah operasi : %s \n”,kata1);
strcpy(kata2,data1); //mencopy string data1 disimpan di kata2
printf(“nilai string kata2 setelah operasi : %s \n”,kata2);
hasil = strcmp(data1,data2); //membandingkan data1 dan data2
if (hasil = = 0) printf(“Data1 sama dengan data2”)
else if(hasil< 0) printf(“Data1 lebih kecil dari data2”);
else printf(“Data1 lebih besar dari data2”);
baru = strchr(data2,’C’); //mencari karakter‟C‟ pada data2, hasil disimpan di baru
printf(“\nHasil mencari karakter C : %s”, baru);
return 0; //nilai balik ke fungsi main
}
Output :
panjang string kata1 : 8
Nilai string kata1 setelah operasi : Ibu Kota Jakarta
Nilai string kata2 setelah operasi : ABcd
Data1 lebih besar dari data2
Hasil mencari karakter C : CD
Nilai yang tersimpan pada tiap variabl setelah operasi :
kata1= “Ibu Kota Jakarta” karena menyimpan hasil operasi strcat(kata1,kata2).
kata2 = “Abcd” karena menyimpan hasil opersi strcpy(kata2,data1)
data1 = “Abcd”
data2 = “ABCD”
hasil = lebih besar dari nol karena karakter „c‟ lebih besar dari „C‟
baru = “CD”
d)
COUNTINUATION CHARACTER
Continuation character
Baris
panjang kode tidak nyaman jika aplikasi editor skrip Anda tidak membungkusnya.
Dalam lingkungan seperti itu, jika kode Anda berisi garis panjang dan Anda
ingin dapat membacanya tanpa menggulir secara horizontal, Anda perlu cara untuk
memecah garis panjang. Karena sebuah baris adalah unit sintaksis yang bermakna,
Anda tidak dapat melakukan ini hanya dengan memasukkan karakter kembali.
Sebaliknya, Anda juga harus memasukkan karakter kelanjutan.
TIP
Masalah
yang diselesaikan karakter lanjutan tidak lagi menjadi masalah besar, karena
aplikasi editor skrip saat ini memang membungkus garis panjang.
Karakter
kelanjutan muncul sebagai tanda "tidak logis"; itu adalah codepoint
MacRoman 194, Unicode (dan WinLatin1 dan ISOLatin1) codepoint 172. Karakter ini
biasanya diketik pada Macintosh sebagai Option-L; tetapi sebagai kenyamanan,
dalam aplikasi editor skrip, mengetik Option-Return memasukkan karakter
logical-not dan karakter return, dan merupakan cara biasa untuk melanjutkan
sebuah baris. Sebagai contoh:
atur
ke ¬
1
Ini
adalah kesalahan waktu kompilasi untuk apa pun untuk mengikuti karakter
lanjutan pada baris yang sama selain spasi putih.
Ini
adalah kesalahan kompilasi-waktu untuk baris berikut karakter kelanjutan
menjadi kosong, kecuali apa yang mendahului karakter kelanjutan adalah perintah
yang lengkap, seperti dalam contoh yang sangat konyol ini:
atur
ke 1 ¬
atur
b ke 2
Karakter
lanjutan dalam string literal ditafsirkan sebagai karakter logis-bukan literal.
Untuk memecah string literal panjang menjadi beberapa baris kode untuk
keterbacaan tanpa ...
SUMBER
http://www.materidosen.com/2017/02/pengertian-jenis-dan-contoh-identifier.html https://b3rbagilmu.blogspot.com/2016/06/keyword-dalam-bahasa-c.html (https://www.duniailkom.com/tutorial-belajar-c-jenis-jenis-tipe-data-dalam-bahasa-c/ https://www.petanikode.com/c-variabel/ http://haqcoding.blogspot.com/2017/07/pengertian-deklarasi-di-pemrograman.html
PENGANTAR PEMROGRAMAN BAHASA C
I.
Langkah dalam Membuat Bahasa C
Misal membuat Hello World:
Menulis Program Bahasa C1. Pertama teman-teman buka dulu text editor nya, kalau di linux (gedit) di windows (notepad/notepad++) atau bisa juga memakai compiler yang lain yang ada pada windows seperti Dev C++ atau CodeBlock. Kalau masih bingung mengenai text editor atau compiler silahkan baca Pengenalan Bahasa C.
Tampilan Text Editor (Gedit) di Ubuntu
Tampilan text Editor setelah di save dengan .c
#include<stdio.h>
int main(){
printf(“Hello World !! \n”);
}
·
kata #include<stdio.h> adalah
perintah untuk menginputkan fungsi2 yang ada di library :<stdio.h>
agar bisa kita gunakan dalam menulis program.
·
int main() adalah sebuah main
program(kepala program) kita yang mana berbentuk integer(int) dengan di ikuti
kata main dan tanda () biasanya digunakan untuk membuat sebuah
parameter2 bila program kita sudah banyak. Karena kita hanya ingin menampilkan
“hello world” maka kita kosong kan saja.
catatan : “ kata main() harus kita buat kalau tidak maka program kita
akan Eror, sedangkan kata int sifatnya opsional bisa kita kosongkan ataupun
kita ganti dengan float,double tergantung program yang seperti apa yang
akan kita buat. Tetapi saya akan terus membuat int main() agar lebih mudah
memahaminya”.
·
Tanda {} adalah bahwasanya program kita
harus kita buat di dalam tanda kurung kurawal tersebut agar bisa di compile.
·
Printf adalah perintah untuk menampilkan
sesuatu ke layar. Jadi jika kita buat printf(“Hello World !! \n”); artinya kita
membuat perintah untuk menamiplkan kata Hello World !! ke layar.
4. Program kita telah selesai kita buat, langkah terakhir
adalah tinggal menjalankannya.Catatan : “Kalau memakai Dev C++ atau Codeblock maka tinggal mengcompilenya saja dengan menekan tombol run,maka hasilnya akan muncul”
5. Karena saya memakai text Editor, maka kita mengcompile nya menggunakan terminal di ubuntu atau cmd diwindows.
·
Buka Terminal atau Cmd kalau di windows.
·
Setelah itu masuk ke direktori folder
tempat file hello.c yang kita simpan tadi, contohnya seperti berikut :
* saya menyimpannya di document, ketik perintah :
cd (namafolder)
II.
Struktur Bahasa C
Kode
program yang telah jalankan sebelumnya sangat sederhana, tapi sudah mewakili
struktur dasar dari sebuah bahasa pemrograman C. Berikut kode program tersebut:
1
2
3
4
5
6
|
#include <stdio.h>
int
main(void)
{
printf("Hello,
World!\n");
return 0;
}
|
#include <stdio.h>
Di
baris paling awal, terdapat kode #include. Perintah #include
digunakan untuk memasukkan sebuah file khusus yang memungkinkan kita mengakses
berbagai fitur tambahan dalam bahasa C.
Dalam
contoh diatas, file stdio.h berisi kode program agar nantinya kita bisa
mengakses perintah printf. File stdio.h sendiri merupakan singkatan
dari Standard Input/Output.
Dengan
kata lain, agar di dalam kode program nanti kita bisa menggunakan perintah printf,
dibagian paling atas kode program C harus terdapat baris #include
<stdio.h>. File include ini juga sering disebut sebagai header
file, dan karena itu pula menggunakan akhiran .h.
Bahasa
C menerapkan konsep modular, dimana fitur-fitur yang ada di pecah ke
berbagai file. Jika ingin menggunakan perintah tertentu, panggil header file
yang sesuai.
Hasilnya,
ukuran file program yang ditulis menggunakan bahasa C menjadi efisien. Kita
hanya perlu menggunakan header file yang dibutuhkan saja. Namun kebalikannya,
setiap ingin menggunakan perintah tertentu, harus men-include-kan file header
yang dibutuhkan.
int main(void) { }
Satu-satunya
perintah yang harus ada di setiap kode program bahasa C adalah main().
Struktur
main() sendiri pada dasarnya merupakan sebuah fungsi (function).
Isi dari function ini diawali dan diakhiri dengan tanda kurung kurawal ” { ”
dan ” } “. Di dalam tanda kurung inilah “isi” dari kode program penyusun fungsi
main() ditulis.
Kode
int sebelum main() menandakan nilai kembalian atau hasil
akhir dari function main(). Kode int merupakan singkatan dari integer,
yakni tipe data angka bulat.
Dengan
demikian, kode program main() yang saya tulis diatas harus menghasilkan
sebuah angka bulat (menggunakan perintah return yang akan kita bahas
sesaat lagi).
Sedangkan
tambahan void ke dalam main(void) menandakan bawah fungsi main()
tidak membutuhkan nilai input (bahasa inggris void = kosong).
*
Jika anda agak bingung dengan penjelasan ini, bisa dianggap bahwa int
main(void) { } adalah perintah yang mengawali setiap kode program bahasa C.
printf(“Hello, World!\n”);
Perintah
printf digunakan untuk menampilkan sesuatu ke layar. Perintah ini
merupakan bagian dari stdio.h, sehingga jika kita ingin menggunakannya,
harus terdapat baris perintah #include <stdio.h> di bagian paling
awal kode program bahasa C.
Teks
yang ingin ditampilkan ditulis dalam tanda kurung dan di dalam tanda kutip dua,
seperti: printf(“Hello, World!\n”); Hasil dari perintah ini, akan tampil
teks Hello, World! di layar. Tapi apa fungsi tambahan karakter \n?
Jika
ditulis di dalam teks, karakter ” \ ” dikenal sebagai escape character.
Fungsinya untuk menampilkan karakter yang tidak bisa ditulis. Sebagai contoh, \n
merupakan perintah untuk menulis newline character, yakni karakter
penanda baris baru.
Artinya,
perintah printf(“Hello, World!\n”) akan menampilkan teks “Hello,
World!”, kemudian pindah ke baris baru. Bahasa C mendukung berbagai escape
character yang nantinya juga akan kita pelajari.
Setelah
tanda kurung penutup perintah printf, harus ditutup dengan tanda titik
koma (semi-colon), yakni tanda “ ; ”. Setiap perintah bahasa C, harus
diakhiri dengan tanda ini, kecuali beberapa perintah khusus. Lupa menambahkan
tanda titik koma di akhir sebuah perintah merupakan error yang sangat sering
terjadi.
return 0;
Perintah
return 0; berhubungan dengan kode int main(void) sebelumnya.
Disinilah kita menutup function main() yang sekaligus mengakhiri
kode program bahasa C.
Return
0 artinya kembalikan nilai 0
(nol) ke sistem operasi yang menjalankan kode program ini. Nilai 0 menandakan
kode program berjalan normal dan tidak ada masalah (EXIT_SUCCESS).
Kita
juga bisa menulis return 1, return 99, return -1, dll. Nilai-nilai ini nantinya
bisa digunakan oleh sistem operasi atau program lain. Nilai return selain 0
dianggap terjadi error atau sesuatu yang salah (EXIT_FAILURE).
Apakah
perintah Return 0 ini harus ditulis?
Harus ditulis! jika kita berpatokan ke struktur bahasa C yang ideal.
Namun beberapa compiler (termasuk Code:Blocks yang saya gunakan), akan
“memaafkan” jika perintah ini tidak ditulis dan menambahkan perintah return 0 secara
otomatis (tidak disarankan).
III.
Contoh Bahasa C
Program Pemilihan 2 Kasus
Pemilihan 2 kasus menggunakan perintah if
then else. Pada dasarnya pemilihan dua kasus sama seperti pemilihan 1
kasus. Pada pemilihan 2 kasus “Jika kondisi terpenuhi atau bernilai benar, maka
aksi pertama akan ditampilkan. Namun, jika kondisi tidak terpenuhi atau
bernilai salah, maka aksi kedua akan ditampilkan. Berikut contoh programnya,
// Program Pemilihan 2 kasus
#include <stdio.h>
int main()
{
int Angka;
printf("Masukkan sebuah bilangan : ");
scanf("%d",&Angka);
if(Angka >0)// Pemilihan 1 Kasus
{ printf("Angka yang Anda masukkan adalah : POSITIF");
// Statement Benar akan ditampilkan } else { printf("Angka yang Anda masukkan adalah : NEGATIF");
// Statement Salah akan ditampilkan } return0;
}
Berikut output program di atas :Program Pemilihan 3 Kasus
Menggunakan perintah if then bertingkat
Perintah ini digunakan untuk menguji kondisi
lebih dari 2 kasus. Jika salah satu kondisi terpenuhi, akan ditampilkan pada
layar monitor. Berikut contoh programnya,
// Program pemilihan 3 kasus menggunakan if bertingkat
#include <stdio.h>
int main () {
int Angka;printf("Masukkan sebuah Angka : ");
scanf("%d",&Angka);
if(Angka >0){
printf("Angka yang Anda masukkan POSITIF");
// Pernyataan jika Angka > 0 }elseif(Angka <0){
printf("Angka yang Anda masukkan adalah NEGATIF");
// Pernyataan jika Angka < 0 }else{
printf("Angka yang Anda masukkan adalah NOL");
// Pernyataan lainnya } return0;
}
Berikut output program di atas :
KOMPONEN BAHASA C
A.
Character
Set
Character Set ASCII
Pada awal generasi digunakannya sistem komputer, ASCII Character Set yang mulai ada sejak 1960-an menjadi standar yang digunakan di sebagian besar sistem komputer untuk menampilkan karakter.ASCII merupakan kependekan dari American Standard Code for Information Interchange, sehingga dapat ditebak bahwa ASCII ini dibuat oleh Amerika, yang memang ditujukan untuk mengakomodasi karakter yang digunakan pada bahasa mereka dan oleh sebab itu ASCII generasi pertama ini sering disebut US-ASCII.
Character Set ASCII hanya terdiri dari 128 karakter yang terdiri dari karakter nyata (huruf, angka, simbol dan tanda baca) dan karakter tidak nyata (tab, enter, alt, dsb), contoh karakter ASCII adalah seperti yang ada pada tombol keyboard yang kita gunakan sekarang ini, untuk lebih lengkapnya dapat dilihat pada tabel ini.
Kenapa hanya 128 karakter? ya karena memang pada saat itu hanya karakter tersebut yang diperlukan dan sistem yang ada hanya dapat menampung sejumlah karakter terebut dan sampai dengan saat ini saya rasa masih cukup memadahi.
Setiap karakter yang ada pada ASCII cukup ditampung kedalam 7 bit binary digit, sehingga dapat dikatakan ASCII menggunakan 7 bit sistem encoding, contoh:
Karakter
|
Binary
|
Karakter
|
Binary
|
a
|
1100001
|
@
|
1000000
|
b
|
1100010
|
#
|
0100011
|
c
|
1100011
|
%
|
0100101
|
1
|
0110001
|
!
|
0100001
|
2
|
0110010
|
$
|
0100100
|
3
|
0110011
|
&
|
0100110
|
Character Set Latin-1 atau ISO/IEC 8859-1
Semakin berkembangnya penggunaan komputer dan internet, maka negara-negara maju lain di Eropa khususnya yang menggunakan karakter khusus seperti penggunaan accent (tanda diatas karakter) yang digunakan di negara Jerman, Swedia, Prancis, Belanda, dll merasakan keterbatasan ASCII.Hal tersebut karena dengan ASCII, mereka tidak dapat menggunakan karakter yang ada pada bahasa mereka, sehingga pertukaran data tidak dapat dilakukan dengan baik.
Permasalahan tersebut menjadi isu penting dan akhirnya pada tahun 1987 direlease versi pertama dari ISO-8859-1 atau Latin1 (beberapa ada yang menggunakan istilah Extended ASCII, 8 bit ASCII atau ASCII – bukan US-ASCII) yang diadopsi dari ECMA Standard (European Computer Manufacturers Association).
Angka 1 pada ISO-8859-1 berarti standard encoding pertama dari seri ISO-8859 yang terdaftar di ISO.
Karakter yang ada pada ISO-8859-1 hanya terdiri dari karakter ASCII ditambah dengan beberapa karakter yang khusus digunakan di bahasa negara-negara Eropa Barat, penambahan ini dimulai dari karakter ke 128 s.d 255.
Kenapa 128 bukan 129? bukankah ASCII jumlah karakternya 128? ya betul, ASCII jumlah karakternya 128, namun urutan karakter dimulai dari 0, sehingga penghitungan karakter dimulai dari 0.
Karakter yang ada pada ISO-8859-1 dapat dilihat di http://www.ascii-code.com/
Karakter pada Latin1 tetap berukuran 1 byte, karena seperti disebutkan sebelumnya bahwa masih terdapat 1 bit tersisa pada sistem encoding ASCII, penggunaan 1 bit ini berdampak bertambahnya kombinasi bilangan biner sehingga dalam sistem 8 bit dapat diperoleh karakter berjumlah 256(2^8).
Penggunaan 1 byte ini disebut juga single byte encoding. Berikut ini contoh karakter Latin1 dan nilai binary nya:
TEXT
|
ASCII
|
BINARY
|
TEXT
|
ASCII
|
BINARY
|
ä
|
chr(228)
|
11100100
|
ø
|
chr(248)
|
11111000
|
å
|
chr(229)
|
11100101
|
ù
|
chr(249)
|
11111001
|
æ
|
chr(230)
|
11100110
|
ú
|
chr(250)
|
11111010
|
ç
|
chr(231)
|
11100111
|
ý
|
chr(253)
|
11111101
|
è
|
chr(232)
|
11101000
|
þ
|
chr(254)
|
11111110
|
é
|
chr(233)
|
11101001
|
ÿ
|
chr(255)
|
11111111
|
Munculnya Latin1 ini ternyata belum dapat mengatasi keterbatasan penggunaan karakter, seperti penggunaan karakter di negara negara Eropa Tengah dan Timur, oleh karena itu perlu dikembangkan character set lain yang dapat mengakomodasi karakter tersebut.
Mulailah bermunculanlah character set baru yang diberi nama ISO-8859-2 atau Latin2, ISO-8859-3 atau Latin3, dan seterusnya hingga ISO-8859-16 yang direlease tahun 2001. Masing masing character set spesifik untuk bahasa tertentu dan tujuan tertentu. Untuk detail seri ISO 8859 dapat dibaca di wikipedia.
Secara umum format character set ISO-8859-x adalah karakter ke 0 s.d 127 untuk karakter ASCII sedangkan sisanya karakter tambahan. contoh:
Encoding
|
#0 – #127
|
#128 – #255
|
ISO-8859-5
|
ASCII
|
Cyrillic
|
ISO-8859-6
|
ASCII
|
Arabic
|
ISO-8859-7
|
ASCII
|
Greek
|
ISO-8859-8
|
ASCII
|
Hebrew
|
Unicode (character set terakhir?)
Seperti pembahasan diatas, ternyata terdapat banyak sekali character set, masing masing dikembangkan hanya untuk penggunaan pada regional tertentu, dan untuk tujuan tertentu, tidak ada character set yang dapat menampung semua karakter yang digunakan oleh semua bahasa.
Hal ini terjadi karena sistem encoding yang dikembangkan masih menggunakan sistem single byte (8 bit) dimana hanya dapat menampung karakter sebanyak 256.Untuk mengatasi hal tersebut, perlu dikembangkan suatu character set yang dapat menampung sekaligus banyak karakter, tidak hanya 256, jika perlu dapat menampung semua karakter yang digunakan oleh semua bahasa di dunia ini, dan yang pasti tidak mungkin bisa menggunakan sistem single byte encoding.
Dilatarbelakangi hal tersebut muncullah Unicode Character Set yang dikembangkan oleh Unicode Consortium.
Saat ini Unicode dapat mengcover lebih dari 1.100.000 karakter, angka tersebut sangat cukup untuk mengakomodasi semua karakter yang digunakan semua bahasa di dunia ini.
Dari waktu kewaktu, karakter baru terus ditambahkan, tidak hanya bahasa resmi negara tetapi juga bahasa daerah termasuk aksara jawa, Bali Bugis, Sunda, dll
Sampai dengan saat ini (Unicode Versi 8.o – di release 17 Juni 2015) jumlah karakter yang ditambahkan baru sebanyak 120.737, sehingga baru terpakai sekitar 12% dari kapasitas yang ada, masih sisa tersisa 88% yang masih sangat cukup untuk penggunaan jangka panjang.
Dengan perkembangan yang ada dapat dikatakan bahwa unicode characterset is the last character set. Waktu yang akan membuktikannya.
Character Set UTF-16 dan UCS-2
Pada awal generasi Unicode Standard (versi 1.0.0), diperkenalkan character set yang mampu menampung karakter lebih dari 256, saat itu digunakan sistem fixed width encoding dengan basis 16 bit (2 x 8 bit) atau disebut dengan istilah double byte encoding.Sistem encoding ini sama dengan yang digunakan pada UCS-2 (2-byte Universal Character Set) – didefinisikan oleh ISO 10646, yang sudah terlebih dahulu diperkenalkan.
Pada generasi awal unicode ini belum dikenal istilah UTF-16 karena memang hanya satu sistem encoding yang digunakan.
Dengan basis 16 bit, karakter yang ditampung mencapai 65.536 karakter (216), sistem tersebut berlangsung hingga Unicode versi 1.1.0 (1991 s.d 1995).
Semakin lama sistem encoding yang ada tidak cukup menampung karakter baru yang belum ditambahkan, oleh karena itu diperkenalkanlah UTF-16 atau disebut juga Extended UCS-2 yang direlease tahun 1996.
UTF-16 merupakan sistem variable length encoding yang berarti setiap code point (kode yang mencerminkan suatu karakter) di encode menggunakan satu atau dua kali 16-bit (1 code unit = 16 bit).
Sederhananya setiap karakter unicode di encode menjadi 16 bit (1 code unit) atau 32 bit (2 code unit) tergantung jenis karakternya.
16 bit pertama digunakan untuk mengencode karakter yang ada pada Basic Multilanguage Plane BMP (karakter ke 0 s.d 65.535), sedangkan 16 bit berikutnya digunakan untuk mengencode karakter tambahan.
BPM sudah mencakup sangat banyak karakter dan simbol, mulai dari bahasa yang umum hingga yang rumit seperti CJK (China, Jepang, Korea), disamping itu juga sudah menampung aksara daerah dari berbagai negara, seperti yang ada di kita: aksara Jawa (Unicode versi 5.2), Bali, Sunda dan Batak.
Perbedaan karakter yang dapat diencode oleh UTF-16 dan UCS-2 tampak seperti pada tabel berikut:
Encoding
|
#0 – #65535
|
> 65.535
|
UTF-16
|
BPM
|
Karakter
Lain
|
UCS-2
|
BPM
|
–
|
Meski demikian, karakter yang semestinya bisa diencode menggunakan sistem 8 bit, harus diencode menggunakan sistem 16 bit, seperti pada karakter ASCII, yang artinya yang seharusnya bisa disimpan menggunakan ruang 1 byte dipaksa menggunakan 2 byte, sehingga UTF-16 ini cocok digunakan pada aplikasi yang mementingkan speed dan tidak mempermasalahkan ruang penyimpanan.
Kelemahan lain adalah sama sekali tidak mendukung karakter ASCII, karena jelas sistem encoding yang digunakan berbeda, sehingga karakter yang disimpan dengan sistem encoding ASCII tidak dapat dibuka oleh aplikasi yang menggunakan sistem encoding UTF-16.
Saat ini UTF-16 masih populer digunakan, diantaranya: bahasa pemrograman Java, C#, Objective C dan Windows API
Character Set UTF-32 atau UCS-4
UTF-32 secara resmi menjadi bagian dari Unicode standar pada versi 3.1.0 yang dipublikasikan tahun 2001, sistem encoding ini sama dengan yang digunakan pada UCS-4 (4-byte Universal Character Set) – didefinisikan oleh ISO 10646, yang sudah terlebih dahulu diperkenalkan.Angka 32 pada UTF berarti 32 bit dan 4 pada UCS berarti 4 byte, yang dapat diartikan bahwa space yang digunakan untuk menyimpan suatu karakter adalah 4 byte atau 32 bit.
UTF-32 merupakan alternatif dari UTF-16, jika pada UTF-16 terdapat penggunaan sistem doubel 16 bit (untuk karakter ke 65.535 keatas), UTF-32 menggunakan fixed – width encoding, dengan base 32 bit (1 code unit = 32 bit), dimana semua karakter disimpan menggunakan sistem 32 bit encoding.
Akibatnya setiap karakter membutuhkan ruang penyimpanan sebesar 4 byte (32 bit), meskipun sebenarnya terdapat karakter yang hanya menggunakan 8 bit, sehingga pada UTF-32, yang terisi hanya 8 bit pertama, sisanya bernilai 0.
Dengan model encoding seperti ini, binary dapat diindex/diurutkan (mendukung byte order dependent) – seperti pada ASCII, sehingga pencarian suatu karakter dapat dilakukan lebih cepat.
Meski demikian encoding ini memiliki kelemahan yaitu memakan banyak space dan memory, yang tentu saja tidak efisien, contoh kata halo pada UTF-32 membutuhkan ruang penyimpanan 16 byte, sedangkan pada ASCII cukup 4 byte.
Contoh karakter dan nilai binary nya pada UTF-32:
TEXT
|
Chr Ke
|
BINARY
|
!
|
32
|
00000000
00000000 00000000 00100001
|
Љ
|
1025
|
00000000
00000000 11111001 01100101
|
65.537
|
00000000
00000010 00100111 01001000
|
Character Set dan Character Encoding Utf-8
Generasi terakhir dari sistem encoding UTF adalah UTF-8. UTF-8 resmi masuk ke Unicode Standar pada versi 5.0.0 (2006). Sistem encoding UTF-8 hingga saat ini paling banyak digunakan untuk pertukaran data, terutama pada media internet, yang hingga saat ini sudah mencapai angka 85.3% (27 Oktober 2015) dan akan terus meningkat.UTF-8 menggunakan sistem variable length encoding dengan basis 8 bit (1 code unit = 8bit), angka ini tercermin pada angka 8 yang berada di belakang UTF.
Sistem variable length berarti karakter di encoding menggunakan pola tertentu dengan panjang bit tidak tetap tergantung jenis karakternya, bisa 8, 16, 24 atau 32 bit. Pembagian penggunaan bit adalah sebagai berikut:
- 8 bit (1 byte) encoding digunakan untuk karakter 0 s.d 127, sama persis dengan yang digunakan ASCII.
- 16 bit (2 byte) encoding digunakan untuk karakter 128 s.d 2047. Contoh: Huruf Latin Extended (dengan tilde (Ã), macron (¯), acute(Á), grave(À) dan accents (tanda diatas huruf) lainnya), huruf kirilitz (cyrillic) yang digunakan beberapa negara Slavia: Rusia, Ukraina, Bulgaria dan Serbia (Contoh: КАЛИФОРНИЯ) , Yunani (Greek), contoh: μαγεια, Armenia, Ibarani (Hebrew), contoh: הוא עובד, Arab contoh: اللغة العربية, dan lainnya.
- 24 bit (3 byte) encoding digunakan untuk karakter 2048 s.d 65.535. Contoh huruf Cina, Jepang dan Korea.
- 32 bit (4 byte) encoding untuk karakter 65.536 s.d 1,112,064
Pada UTF-8 sistem 1 byte encoding yang digunakan sama persis dengan sistem yang digunakan pada ASCII sehingga UTF-8 kompatibel dengan karakter ASCII, yang artinya karakter yang disimpan menggunakan sistem encoding ASCII dapat dibuka menggunakan sistem encoding UTF.
Perbandingan bit yang digunakan
Perbandingan bit yang digunakan pada ketiga sistem encoding yang ada pada Unicode Standar tampak seperti pada tabel berikut:
Range (Hexadecimal)
|
Range (Decimal)
|
UTF-8
|
UTF-16
|
UTF-32
|
000000
– 00007F
|
0-127
|
1
|
2
|
4
|
000080
– 00009F
|
128-2.047
|
2
|
||
0000A0
– 0003FF
|
||||
000400
– 0007FF
|
||||
000800
– 003FFF
|
2.048-65.535
|
3
|
||
004000
– 00FFFF
|
||||
010000
– 03FFFF
|
65.536-1.114.111
|
4
|
4
|
|
040000
– 10FFFF
|
Ambiguitas Character Set dan Caharacter Encoding
Dari uraian diatas secara jelas dapat kita bedakan apa itu character set dan apa itu sistem encoding, namun kenyataannya terkadang kedua istilah ini membingungkan.Pada awal munculnya ASCII standard hingga ISO-8859-x istilah character set dan sistem encoding merujuk ke standar itu sendiri, misal istilah ASCII Character Set digunakan untuk menyebut character set yang digunakan ASCII, dan ASCII encoding untuk menyebut sistem encoding pada ASCII.
Meskipun sebenarnya istilah ASCII lebih tepat digunakan untu character set, begitu juga dengan ISO-8958-1 atau Latin1 standar.
Pada awal muncul Unicode standar pun, istilah yang sama masih masih dapat digunakan, namun setelah muncul UTF-16, istilah character set dan sistem encoding mulai agak membingungkan
Banyak yang menyebut UTF sebagai character set dan Unicode adalah sistem encoding padahal sebenarnya UTF adalah sistem encoding dan Unicode lebih tepat digunakan untuk menyebut character set, walaupun Unicode sendiri hanya merupakan suatu standar.
Contoh pada dokumen HTML sering kita jumpai meta tag berikut:
<meta Content-Type: text/html; charset=utf-8>
Dalam mengartikan tag diatas, mungkin beberapa orang menganggap bahwa
charset="utf-8" maksudnya
adalah character set yang digunakan adalah UTF-8, padahal sebenarnya yang dimaksud
disini adalah sistem encoding yang digunakan adalah UTF-8.Hal yang sama juga terjadi pada istilah dalam dunia database, seperti MySQL yang menyebut utf8, utf16, utf32 dan utf8mb4 sebagai character set.
Jadi Character Set mana yang sebaiknya digunakan?
Berdasarkan uraian diatas, selanjutnya muncul pertanyaan, jadi sebaiknya character set mana yang sebaiknya digunakan? hal ini tergantung dari jenis karakter yang akan kita digunakan, beberapa kemungkinan yang ada:- Aplikasi/website yang kita bangun menggunakan satu bahasa/beberapa berbahasa yang hanya menggunakan jenis huruf alphabet biasa (seperti Bahasa Indonesia atau Bahasa Inggris), maka cukup menggunakan character set ASCII (ascii pada MysQL) atau ISO-8859-1 (Latin1 pada MySQL).
Kenapa tidak utf8? bukankan utf8 juga
menyimpannya sebesar 1 byte?
Hal ini tergantung dari sistem
penyimpanan yang kita gunakan, pada database tertentu seperti MySQL penggunaan
utf8 memungkinkan penggunaan ruang penyimpanan lebih dari 1 byte tergantung
tipe data yang digunakan, sedangkan Latin1, ASCII, dan sejenisnya pasti
menggunakan ruang 1 byte.
- Bahasa yang kita gunakan menggunakan bahasa tertentu, misal bahasa Arab, maka dapat menggunakan character set ISO-8859-6 yang memang di desain untuk penggunaan arabic alphabet namun tidak termasuk character tambahan seperti yang digunakan pada alphabet bahasa Urdu dan Persia.
Namun jika character mengandung
character urdu seperti pada quran dan hadis, character set tersebut
tidak bisa digunakan lagi karena character yang digunakan lebih kompleks,
seperti ( لاگا,
شيرِ),
sehingga pilihannya utf-16 atau utf-8.
Pada utf-16 character ini di encode
menggunakan sistem 2 byte dan 3 byte pada utf-8, sehingga lebih efisien
menggunakan utf-16.
- Aplikasi yang kita kembangkan ditujukan untuk pengguna seluruh dunia (world wide) sehingga mau tidak mau kita harus dapat menampung semua kemungkinan character yang ada.
Untuk kondisi seperti ini mau tidak
mau kita harus menggunakan utf-16 atau utf-8, namun lebih menguntungkan utf-8
karena untuk character alphabet disimpan hanya dalam 1 byte.
Kesimpulan
Character set merupakan sekumpulan karakter yang terstandardisasi.Character set pertama adalah ASCII yang diperkenalkan tahun 1960, sejak itu muncul berbagai character set yang semuanya ditujukan untuk menampung karakter yang dibutuhkan namun terbatas hanya untuk regional tertentu dan tujuan tertentu.
Tahun 1991 mulai diperkenalkan Unicode Standar atau sering disebut Unicode Character Set yang dapat menampung semua karakter yang ada baik yang sudah ada pada character set lain maupun yang belum terdefinisi, dan hingga saat ini Unicode merupakan satu standar yang paling banyak digunakan terutama untuk pertukaran data di internet
B.
IDENTIFIER
Identifier adalah sebuah pengenal atau
pengidentifikasi yang kita deklarasikan agar kompiler dapat mengenalinya. atau
Identifier juga biasa diartikan sebagai nama yang diberikan untuk penamaan
objek, Identifier dapat berupa nama variabel, nama konstanta, nama fungsi, nama
prosedur maupun nama namescape. namu pada kesempatan ini kita akan batasi
pembahasannya pada identifier yang berperan sebagai variabel dan konstanta
saja.
Identifier yang berperan sebagai
variabel dan konstanta berfungsi untuk menampung sebuah nilai yang digunakan
dalam program. Hal ini digunakan untuk memudahkan proses penanganan data atau
nilai, misalnya untuk memasukkan dan menampilkan nilai. Sebagai gambaran
dibawah ini adalah sebuah contoh program yang menggunakan 2 buah identifier
didalamnya.
Contoh Identifier dalam C++
#include <iostream>
using namespace std;
int main ()
{
char Teks [20]; int X;
cout<<"Masukkan sebuah kata : ";cin>>Teks;
cout<<"Masukkan sebuah angka : ";cin>>X;
cout<<"\nKata yang di masukkan : "<<Teks;
cout<<"\nAngka yang di masukkan : "<<X;
return 0;
}
using namespace std;
int main ()
{
char Teks [20]; int X;
cout<<"Masukkan sebuah kata : ";cin>>Teks;
cout<<"Masukkan sebuah angka : ";cin>>X;
cout<<"\nKata yang di masukkan : "<<Teks;
cout<<"\nAngka yang di masukkan : "<<X;
return 0;
}
Pada program diatas
kita mempunyai 2 buah identifier, yaitu Teks dan X. Pada saat
program dijalankan, identifier tersebut akan digunakan untuk menyimpan nilai
yang dimasukkan dari keyboard. Dalam C++, proses penyimpanan nilai seperti ini
dinyatakan dengan perintah "cin" yang menggunakan operator
">>". Berbeda dengan "cin", perintah "cout"
digunakan untuk menampilkan nilai, dimana operator yang digunakan adalah
operator "<<".
Dalam C++ sendiri dalam pembuatan Identifier kita dapat menuliskannya dengan karakter sebagai berikut:
Dalam C++ sendiri dalam pembuatan Identifier kita dapat menuliskannya dengan karakter sebagai berikut:
- Huruf "a" sampai "z"
- Huruf "A" sampai "Z"
- Bilangan antara "0" sampai "9"
- Underscore " _ "
6 Ketentuan membuat Identifier
Dalam menentukan atau membuat
identifier dalam program, kita harus memperhatikan hal-hal berikut:
1. Case sensitive
Karena bahasa C++ bersifat case
sensitive, maka C++ juga akan membedakan identifier yang ditulis dengan huruf
kapital dan huruf kecil. Misalnya identifier ABC tentunya akan
berbeda dengan identifier aBC.
2. Tidak boleh diawali dengan
Angka
Identifier tidak boleh diawali
dengan karakter yang berupa angka, berikut contohnya:
3. Tidak menggunakan spasi
Identifier tidak boleh mengandung
spasi, biasanya spasi diganti dengan underscore "_" , berikut
contohnya:
4.
Tidak menggunakan karakter simbol
Identifier tidak boleh
menggunakan karakter-karakter simbol (#,$,%,^,!,@,?, dll), berikut contohnya:
5. Tidak menggunakan kata kunci
(keyword)
Identifier tidak boleh
menggunakan kata kunci (keyword) yang terdapat pada C++, berikut contohnya:
6. Sesuaikan penamaan
Nama identifier sebaiknya disesuaikan dengan kebutuhan, artinya jangan sampai orang lain bingung hanya kara kita salah / asal dalam penamaan identifier, contohnya:
Nama identifier sebaiknya disesuaikan dengan kebutuhan, artinya jangan sampai orang lain bingung hanya kara kita salah / asal dalam penamaan identifier, contohnya:
Contoh Identifier sebagai Konstanta dalam C++
Konstanta adalah jenis identifier
yang bersifat konstan atau tetap, artinya nilai dari konstanta didalam program
tidak dapat diubah.berikut Contoh Identifier sebagai Konstanta dalam C++:
Contoh Identifier sebagai Variabel dalam C++
Berbeda dengan konstanta yang
mempunyai nilai tetap, variabel adalah sebuah identifier yang mempunyai nilai
dinamis. Arti kata "dinamis" disini bermaksud bahwa nilai variabel
tersebut dapat kita ubah sesuai kebutuhan dalam program. berikut Contoh
Identifier sebagai Variabel dalam C++, jangan lupa amati perbedaanya dengan
Identifier sebagai konstanta:
{kind=link}
C.
KEYWORD
Ada beberapa keyword dalam bahasa C, diantaranya:
KEYWORD
|
KETERANGAN
|
Auto
|
Keyword auto digunakan untuk
membuat variabel lokal. Namun demikian keyword ini jarang digunakan
|
Break
|
Digunakan untuk keluar dari fo,
for atau loop while dengan melewati kondisi loop yang normal. Keyword ini
juga digunakan untuk keluar dari perintah switch
|
Switch
|
Perintah switch adalah bagian
dari bebrapa perintah yang daa pada C. Perintah ini digunakan untuk
pembuatan rute satu dengan bebrapa cara yang berbeda. Tiap keberhasilan
perintah dapat berasal dari satu perintah sampai beberapa perintah, panjang
porsi default dapat dipakai. Switch akan bekerja dengan pengontrolan
"control-var" terhadap konstanta. Jika telah diketemukan suatu
keserasian, makan pelaksanaan perintah tersebut berhasil. Jika urutan
perintah yang berhubungan dengan case yang sesuai dengan nilai dari
control-var yang tidak berisi break, maka suatu eksekusi perintah akan
berlanjut ke case selanjutnya, dan akan terus berjalan sampai perintah break
diketemuan atau sampai perintah switch berakhir.
|
Case
|
perintah yang ada dalam perintah
switch untuk membandingkan argumen dan parameter
|
Char
|
Tipe data yang digunakan untuk
membuat karakter variasi
|
Const
|
berasal dari kata
"constant" modifier "const" akan mengatakan pada
compiler bahwa variabel yang mengikuti idak dapat dimodifikasi, namun
demikian saat dideklarasikan variable const dapat diberi nilai awal
|
Continue
|
Digunkan untuk menyediakan porsi
code pada suatu loop dan memaksa "conditional test" untuk
ditampilkan
|
Default
|
digunakan pada perintah switch
yang memberi tanda default blok dari code yang akan dibuat jika tidak ada
kecocokan pada switch
|
Do
|
Merupakan salah satu dari
konstruksi loop yang ada pada C. Jika hanya satu perintah yang diulang, maka
tanda kurung tidak diperlukan. Tanda kurung disini hanya memperjelas suatu
perintah. Loop do adalah satu satunya perintah dalam C yang selalu minimal
satu interasi, sebab suau ondisi akan diuji pada bagian bawah loop. Loop do
biasanya dipakai untuk membaca file disk
|
Double
|
Adalah suatu penentu tipe data
yang digunakan untuk membuat "double-percision" variabel
"floating-point"
|
If
|
Suatu fungsi yang mendeklarasikan
sebuah persyaratan. Jika persyaratan itu tidak terpenuhimaka perintah tidak
akan dijalankan atau menjalankan perintah else
|
Else
|
Suatufungsiyang digunkan sebagai
alternatif dalam fungsi if
|
Enum
|
Digunakan untuk membuat
enumerasi(enumeration). Enumerasi adalah suatu daftar yang sederhana dari
konstanta integer yang diberi nama. Oleh sebab itu, tipe data enum ini
menentukan apa yang dibandingkan dalam daftar tersebut
|
Extern
|
Tipe data modifier yang digunakan
untuk memberitahu compiler bahwa suatu variabel telah dibuat li lai tempat
daam program. Tipe ini sering digunakan pada kata penghubung dengan susunan
file terpisah yang memperlakukan data global yang sama serta digabungkan
bersama. Pada dasarnya extern ini memberitahu compiler tentang tipe variabel
tanpa harus membuat variabel itu sendiri
|
Float
|
Tipe data apecifier yang
digunakan untuk membuat variabel floating-point
|
For
|
Loop yang memungkinkan pemberian
huruf awal dan kenaikan secara otomatis dari variabel counter
|
Goto
|
Akan menyebabkan program melompat
pada lael yang ditentukan dengan perintah goto
|
int
|
Tipe data specifieryang digunakan
untuk membuat variabel integer (bilangn bulat)
|
Long
|
Tipe data modifier yang digunakan
untuk membuat variabel integer menjadi double-length
|
Register
|
Adalah modifier penyimpanan yang
digunakan untuk meminta agar satu pemasukan pada variabel dioptimalkan
kecepatanya. Secara tradisional register hanya dapat digunakan pada variabel
integer dan karakter, register tersebut menyebabkan variabel-variabel
tersebut disimpan dalam register CPU sebagai pengganti dari ditempatkannya
pada memory. Standar ANSIC telah diperluas definisinya agar dapat memasukkan
semua tipe data. Namun demikian data selain integer dan karakter biasanya
tidak dapat disimpan di CPU register. Untuk tipe data yang lain baik berupa
cache memori akan dipakai yang kemudian meminta register untuk disimpan.
Register hanya dapat digunakan pada variabel lokal
|
Retur
|
Perintah return akan memaksa
suatu pengembalian dari fungsi dan dapat digunakan untuk mentransferkembali
suatu angka pada return pemanggilan
|
Short
|
Modifier tiper data yang
digunakan untuk mendeklarasikan integer pendek
|
Signed
|
Tipe modifier signed digunakan
untuk menentukan suatu tipe dana signed-char
|
Sizeof
|
Akan mengembalikan panjang
variabel tipe yang mendahuluinya. Jikan yang mendahului adalah suatu
variabel maka tanda kurung bersifat optional
|
Static
|
Tipe data modifier yang digunakan
untuk menyuruh compiler agar membuat penyimpanan yang permanen untuk
variabel lokal yang mendahuluinya. Hal ini memungkinkan suatu variabel yang
telah ditentukan mempertahankan nilai antara pemanggilan fungsi
|
Struc
|
digunakna untuk membuat variabel
kompleks atau konglomerat, yang disebut :structure", yang terbuat dari
satu elemen tipe data
|
Typedef
|
keyword typedef berguna untuk
membuat alias dari suatu tipe data
|
Union
|
Union digunakan untuk menunjukkan
dua variabel atau lebih pada lokasi memori yang sama.
|
Unsigned
|
"unsigned" adalah tipe
data modifier yang memerintahkan compiler untul< menghapus tanda bit dari
suatu integer dan menggunakan seluruh bit untuk keperluar arithmetic. Hal
semacam ini menyebabkan ukuran integer terbesar menjadi dobel tapi hanya
terbatas pada angka-angka positif saja.
|
Void
|
Tipe specifier "void"
pada pokoknya digunakan untuk secara jelas mendeklarasikan fungsi yang tidak
mengembalikan suatu nilai (dalam arti penuh), tipe ini juga digunakan untuk
membuat pointer "void" (pointer pada "void"), yaitu
pointer generic yang dapat menunjukkan beberapa tipe object.
|
Volatile
|
Modifier "volatile"
digunakan untuk memberitahu Compiler bahwa suatu variabel mungkin telah
mempunyai suatu isi yang telah dipilih dengan cara yang tidak ditentukan
oleh suatu program. Contoh, variabel-variabel yang diubah dengan hardware
seperti "realtime clock", 'Interrupt" atau input-input yang
lain, harus dinyatakan sebagai volatile
|
While
|
Adalah suatu loop. Jika suatu
perintah tunggal adalah object dari "while", maka tanda kurung
dapat dihilangkan, "while" akan menguji kondisinya pada bagian
atas suatu loop. Oleh sebab itu jika kondisinya salah untuk memulai,maka
loop tidak akan berjalan, meskipun hanya sekali. Kondisi tersebut mungkin
dapat berupa suatu ekspresi.
|
D. TIPE DATA
Jenis-jenis Tipe Data dalam Bahasa C
Terdapat 8 tipe data di dalam bahasa pemrograman C yang bisa dibagi ke dalam 4 kelompok besar: tipe data dasar, tipe data turunan, tipe data bentukan, dan tipe data void.1. Tipe Data Dasar
Sesuai dengan namanya, tipe data dasar adalah tipe data paling dasar yang tersedia di dalam bahasa pemrograman C. Terdapat 3 jenis tipe data dasar:
- Char: tipe data yang berisi 1 huruf atau 1 karakter.
- Integer: tipe data untuk menampung angka bulat.
- Float: tipe data untuk menampung angka pecahan.
2. Tipe Data Turunan
Tipe data turunan berasal dari tipe data dasar yang dikelompokkan atau di modifikasi. Terdapat 3 tipe data turunan di dalam bahasa pemrograman C:
- Array: Tipe data yang terdiri dari kumpulan tipe data dasar. Tipe data tersebut harus 1 jenis.
- Structure: Tipe data yang terdiri dari kumpulan tipe data dasar. Tipe data tersebut bisa lebih dari 1 jenis.
- Pointer: Tipe data untuk mengakses alamat memory secara langsung.
3. Tipe Data Bentukan (enum)
Sesuai dengan namanya, tipe data bentukan adalah tipe data yang dibuat sendiri oleh kita (programmer). Isinya berupa data-data yang sudah ditentukan. Tipe data bentukan ini dikenal juga sebagai Enumerated Data Type atau disingkat sebagai enum.
4. Tipe Data Void
Tipe data void adalah tipe data khusus yang menyatakan tidak ada data. Penggunaannya khusus untuk beberapa situasi seperti function yang tidak mengembalikan nilai (return void), atau mengisi argumen function dengan nilai kosong.
- Char
- Integer
- Float
- Array
- Structure
- Pointer
- Enum
- Void
Bahasa C memang tidak memiliki tipe boolean bawaan, tapi bisa diakali dengan membuatnya menggunakan tipe data bentukan (enum), atau menggunakan library khusus: stdbool.h.
Sedangkan untuk string, di dalam bahasa C termasuk ke dalam array. String di defenisikan sebagai array dari tipe data char.
E.
KONSTANTA
Mengenal Konstanta pada C
Konstanta adalah sebuah nilai tetapan.Bisa juga dibilang sebagai variabel yang tidak bisa diubah nilainya.
Ada dua cara pembuatan konstanta pada C:
- Menggunakan
#define; - dan Menggunakan
const.
define:#include<stdio.h>
#define SEPULUH 10 #define VERSI 4.5 #define JENIS_KELAMIN 'L' voidmain(){
printf("isi konstanta SEPULUH adalah %i\n", SEPULUH);
printf("isi konstanta VERSI adalah %f\n", VERSI);
printf("isi konstanta JENIS_KELAMIN adalah %i\n", JENIS_KELAMIN);
}isi konstanta SEPULUH adalah10
isi konstanta VERSI adalah 4.500000Contoh menggunakanisi konstanta JENIS_KELAMIN adalah76
const:#include<stdio.h>
voidmain(){
constdoublePI=3.14;
constJENIS_KELAMIN='P';
constVERSI=11;
printf("isi konstanta PI adalah %f\n", PI);
printf("isi konstanta JENIS_KELAMIN adalah %i\n", JENIS_KELAMIN);
printf("isi konstanta VERSI adalah %f\n", VERSI);
}isi konstanta PI adalah 3.140000isi konstanta JENIS_KELAMIN adalah80
isi konstanta VERSI adalah 3.140000#define dan const
terletak pada format penulisannya.Pada
#define kita tidak
perlu menuliskan tipe data, sedangkan const
harus.Pada
#define kita tidak
membutuhkan titik koma di akhir, sedangkan pada const kita harus menuliskan titik koma.Posisi penulisan untuk
#define
dan const bisa ditulis di
dalam main() maupun di luar.Oh iya, untuk nama konstanta disarankan menggunakan huruf kapital untuk menandakan itu sebuah konstanta.
Apa yang akan terjadi jika saya mencoba mengisi nilai ke dalam konstanta?
Ya programnya akan error.
F.
VARIABEL DAN ARRAY
Variable Array adalah
kumpulan dari beberapa nilai yang mempunyai tipe yang sama. Misalkan interger semua,
float semua dan sebagainya. Untuk membedakan antara nilai satu dengan
lainnya digunakan suatu subscript yang sering disebut index. Suatu varriabel
array dapat digunakan untuk menyimpan beberapa nilai dengan tipe sama.
Contohnya variable bilangan[n]. Maka dapat menyimpan beberapa nilai dengan
index mulai dari 0 sampai n-1 yaitu bilangan[0]. Bilangan[1]….. bilangan[n-1].
Nilai subscript dapat berupa konstansta variable dan ekspresi interger.
·
Membuat program untuk
mengurutkan data dengan urutan naik yang dimasukkan melalui keyboard.
Masukkan program
#include <stdio.h>
#include <math.h>
main()
{int data,a,z,b;
printf(“Masukan jumlah data = “);
scanf(“%d”,&data);
int
nilai[data];
for(a=0;a<data;a++){
printf(“data ke %d = “,a+1);
scanf(“%d”,&nilai[a]);
}
for(a=0;a<data;a++){
for(b=a+1;b<data;b++){
if(nilai[a]<nilai[b]){
z=nilai[b];
nilai[b]=nilai[a];
nilai[a]=z;
}}}
printf(“Data urutannya dari terbesar adalah “);
for(a=0;a<data;a++){
printf(“%d”,nilai[a]);
if(a<data-1){printf(“,”);}
}}
Lalu menunjukkan hasil
seperti pada gambar
- Google+
G.
DECLARASI
Deklarasi
(Declare) sangat diperlukan oleh kita jika kita ingin menggunakan pengenal atau
biasa disebut identifier dalam sebuah kode program yang akan kita buat.
Deklarasi di bagi jadi 3 yaitu :
Deklarasi di bagi jadi 3 yaitu :
1.Deklarasi variabel
Bentuk umum sebuah pendeklarasian suatu variable adalah :
2.Deklarasi Konstanta
Di dalam penggunaan konstanta di
bahasa pemrograman C dideklarasikan menggunakan preprocessor #define.
Contohnya:
#define PHI 3.14
#define nom “141206”
#define nama “hakkun”
#define kelas “MM-3”
#define PHI 3.14
#define nom “141206”
#define nama “hakkun”
#define kelas “MM-3”
3.Deklarasi Fungsi
Fungsi
adalah bagian yang terpisah dari sebuah program yang kita buat dan dapat
diaktifkan atau dipanggil di manapun di dalam program. Fungsi dalam sebuah
bahasa pemrograman C ada yang sudah disediakan sebagai fungsi pustaka seperti
printf(), scanf(), getch() dan untuk menggunakannya tidak perlu dideklarasikan.
Fungsi yang perlu dideklarasikan terlebih dahulu adalah fungsi yang dibuat oleh
kita. Bentuk umum deklarasi sebuah fungsi adalah :
Tipe_fungsi nama_fungsi(parameter_fungsi);
Contohnya :
float luas_lingkaran(int jari);
void tampil();
int tambah(int x, int y);
Tipe_fungsi nama_fungsi(parameter_fungsi);
Contohnya :
float luas_lingkaran(int jari);
void tampil();
int tambah(int x, int y);
H.
EXPRESSION
Ekspresi
adalah transformasi nilai menjadi keluaran yang dilakukan melalui suatu
perhitungan (komputasi). Ekspresi terdiri atas operand dan operator, contoh
ekspresi: “a + b”. Untuk pebuah a dan b dinamakan operand, sedangkan “+”
merupakan operator.
Dalam algoritma pemograman terdapat 3 macam ekspresi :
1. Ekspresi Aritmetik
Ekspresi Aritmetik adalah ekspresi yang baik operandnya bertipe numerik dan hasilnya juga bertipe numerik.
Dalam algoritma pemograman terdapat 3 macam ekspresi :
1. Ekspresi Aritmetik
Ekspresi Aritmetik adalah ekspresi yang baik operandnya bertipe numerik dan hasilnya juga bertipe numerik.
Contoh 1.
DEKLARASI
a, b, c : real
i, j, k : integer
ALGORITMA
a * b = c
i + j = k
a, b, c : real
i, j, k : integer
ALGORITMA
a * b = c
i + j = k
Keterangan. Operator yang mempunyai tingkatan lebih tinggi
lebih dahulu dikerjakan daripada operator yang tingkatannya lebih rendah.
Contoh : a/c + b. Yang pertama dikerjakan adalah a/c, kemudian hasilnya
ditambahkan dengan b.
Tingkatan operator aritmetika (dari tertinggi ke terendah) :
(i). /, div, mod
(ii) *
(iii) +, –
(i). /, div, mod
(ii) *
(iii) +, –
Pada ekspresi aritmetik terdapat 2 buah operator yaitu :
– Operator biner, yaitu ekspresi yang operatornya membutuhkan 2 buah operand. Contoh a + b
– Operator Uner, yaitu “-” atau operator yang punya 1 operand contoh “-2”
– Operator biner, yaitu ekspresi yang operatornya membutuhkan 2 buah operand. Contoh a + b
– Operator Uner, yaitu “-” atau operator yang punya 1 operand contoh “-2”
Contoh 2. (Penulisan ekspresi dengan notasi algoritma)
T = 5/9 * (c + 32)
Z = (2*x + y) / (5 * w)
Y = 5((a+b) / (c*d) + m (p + q))
T = 5/9 * (c + 32)
Z = (2*x + y) / (5 * w)
Y = 5((a+b) / (c*d) + m (p + q))
2. Ekspresi Relasional
Ekspresi relasional adalah ekspresi dengan operator <, ≤, >, ≥, =, dan ≠, not, and, or dan xor dengan menghasilkan nilai bertipe boolean (true atau false). Biasanya ekspresi Relasional disebut ekspresi boolean.
Ekspresi relasional adalah ekspresi dengan operator <, ≤, >, ≥, =, dan ≠, not, and, or dan xor dengan menghasilkan nilai bertipe boolean (true atau false). Biasanya ekspresi Relasional disebut ekspresi boolean.
Contoh
DEKLARASI
const ketemu = false
const ada = true
const X = 8
const Y = 12
ALGORITMA
not ada = false
ada or ketemu = true
ada and true = true
X < 5 = false
ada or (X = Y) = true
const ketemu = false
const ada = true
const X = 8
const Y = 12
ALGORITMA
not ada = false
ada or ketemu = true
ada and true = true
X < 5 = false
ada or (X = Y) = true
3. Ekspresi String
Ekspresi String adalah ekspresi dengan operator “+” (operator penyambungan / concatenation).
Ekspresi String adalah ekspresi dengan operator “+” (operator penyambungan / concatenation).
Contoh
DEKLARASI
Kar : char
S : string
{ Contoh-contoh ekspresi untuk tipe string}
(S + Kar) + ‘ C ’
‘Jl.Ganesha’ + ‘No.10’
Kar : char
S : string
{ Contoh-contoh ekspresi untuk tipe string}
(S + Kar) + ‘ C ’
‘Jl.Ganesha’ + ‘No.10’
Menuliskan Nilai ke Piranti Keluaran
Nilai yang disimpan dimemori dapat ditampilkan ke piranti
keluaran (output) dengan instruksi penulisan menggunakan notasi “write”.
write (var1, var2, var3, …, varN)
write (konstanta)
write (ekspresi)
write (nama, konstanta, ekspresi)
write (var1, var2, var3, …, varN)
write (konstanta)
write (ekspresi)
write (nama, konstanta, ekspresi)
Contoh:
DEKLARASI
A,B : integer
NRP : integer
nama_mhs : string
nilai : real
type Jam : record < hh : integer, mm : intege, ss : integer >
J : Jam
ALGORITMA
A <– 8
B <– 6
nama_mhs <– “Andi Baco”
NRP <– 10290056
nilai <– 90.8
J.hh <– 6
J.mm <– 12
J.ss <– 45write (100)
write (A)
write (‘A’)
write (‘Jurusan Teknik Informatika ITB’)
write (‘Nilai A = ’, A)
write (nama_mhs, NRP, nilai)
write (A+B)
write (‘Nilai seluruhnya adalah’, A + B / 2 * 10)
write (J.hh, ‘:’, J.mm, ‘:’, J.ss)
A,B : integer
NRP : integer
nama_mhs : string
nilai : real
type Jam : record < hh : integer, mm : intege, ss : integer >
J : Jam
ALGORITMA
A <– 8
B <– 6
nama_mhs <– “Andi Baco”
NRP <– 10290056
nilai <– 90.8
J.hh <– 6
J.mm <– 12
J.ss <– 45write (100)
write (A)
write (‘A’)
write (‘Jurusan Teknik Informatika ITB’)
write (‘Nilai A = ’, A)
write (nama_mhs, NRP, nilai)
write (A+B)
write (‘Nilai seluruhnya adalah’, A + B / 2 * 10)
write (J.hh, ‘:’, J.mm, ‘:’, J.ss)
I.
Hasil dari Algoritma diatas :
100
8
A
Jurusan Teknik Informatika ITB
Nilai A = 8
Andi Baco, 10290056, 90.8
14
Nilai seluruhnya adalah 70
6 : 12 : 45
100
8
A
Jurusan Teknik Informatika ITB
Nilai A = 8
Andi Baco, 10290056, 90.8
14
Nilai seluruhnya adalah 70
6 : 12 : 45
Berikut adalah contoh-contoh Algoritma dengan menggunakan
teknik pseude-code kemudian ditranslasi ke bahasa pemograman Pascal dan C.
ALGORITMIK:
DEKLARASI
type Titik : record
P : Titik
a,b : integer
nama_arsip, h : string
nilai : real
c : char
ALGORITMA
nilai <– 1200.0
read (P.x, P.y)
read (nama_arsip)
h <– nama_arsip
read (a, b)
read (c)
write (‘Nama Arsip : ’, nama_arsip)
write (‘Koordinat titik adalah :’, P.x, ‘,’, P.y)
write (b, nilai)
write (‘Karakter yang dibaca adalah ’, C )
type Titik : record
P : Titik
a,b : integer
nama_arsip, h : string
nilai : real
c : char
ALGORITMA
nilai <– 1200.0
read (P.x, P.y)
read (nama_arsip)
h <– nama_arsip
read (a, b)
read (c)
write (‘Nama Arsip : ’, nama_arsip)
write (‘Koordinat titik adalah :’, P.x, ‘,’, P.y)
write (b, nilai)
write (‘Karakter yang dibaca adalah ’, C )
J.
STATEMENT
Statement
adalah unsur dasar pembentuk program. Suatu program terdiri dari beberapa
statement dimana komputer akan melakukan tugas tertentu sesuai dengan urutan
statement. Statement ada tiga jenis, yaitu : expression statement, compound
statement, control statement.
Expression
statement adalah suatu expression yang diikuti dengan tanda titik koma (;).
Compound statement adalah adalah dua atau lebih statement yang
dikelompokkan menjadi satu dengan cara memberi batas tanda kurung awal dan
tanda kurung akhir, sehingga tidak perlu diakhiri dengan tanda titik koma pada
akhir dari compound. Control statement adalah statement yang
mengendalikan langkah-langkah program, contohnya for loop, while loop, dan if-else.
Tipe
statemen di Java:
Statement pendeklarasian – statemen
inimeng-create variabel yang dapat digunakan untuk menyimpan data. Contoh:
int i;
String s = "Ini adalah
string";
Pelanggan p = new Pelanggan();
Statement ekspresi – untuk melakukan
kalkulasi. Contoh:
i = a + b;
pajakPenjulalan = totalHarga *
pajakNilai;
System.out.println("Hello,World!");
Statement kontrol, misalnya statemen
if, for, do, while, switch.
K.
SYMBOLIC CONTACT
Symbolic Constant adalah suatu nama
dimana digunakan untuk menggantikan suatu nilai tertentu , sehingga akan lebih
mudah dalam pembacaan suatu program, contohnya #define PI 3,14. PI ditulis
huruf besar untuk membedakan dengan variabel lain.
L.
OPERATOR
Operator Operator Pada Bahasa C
adalah simbol atau karakter yang digunakan oleh program untuk melakukan sebuah
operasi dalam sebuah proses program seperti operasi bilangan dan operasi
string. Bahasa C mengenal penggunaan beberapa operator dengan fungsi yang
berbeda-beda. Setiap operator
memiliki kedudukan atau hirarki saat penanganan
program. Operator dengan hirarki lebih tinggi akan dikerjakan lebih dahulu
dibandingkan operator dengan hirarki lebih rendah.
Operator Operator Pada Bahasa C
Berikut ini operator operator pada bahasa C dan penjelasannya yang sering digunakan pada pemrograman mikrokontroler AVR :1. Operator Aritmatika
Adalah operator yang digunakan untuk operasi bilangan seperti penjumlahan, pengurangan, perkalian, pembagian, modulus, increment dan decrement. Operator aritmatika bisa digunakan pada semua tipe bilangan seperti char, int, long int dan float. Operator aritmatika juga bisa menangani tipe signed dan unsigned.Increment adalah operasi bilangan dimana bilangan hasil merupakan bilangan asal ditambah satu, sedangkan decrement adalah operasi bilangan dimana bilangan hasil merupakan bilangan asal dikurang satu.
Berikut ini beberapa operator aritmatika pada bahasa C :
Operator
|
Nama
|
Contoh
|
Hasil
|
+
|
Penjumlahan
|
z = x + y
|
Penjumlahan
dari x dan y
|
–
|
Pengurangan
|
z = x – y
|
Selisih dari
x dan y
|
*
|
Perkalian
|
z = x * y
|
Perkalian
dari x dan y
|
/
|
Pembagian
|
z = x / y
|
Pembagian x
oleh y
|
%
|
Modulus
|
z = x % y
|
Sisa dari x
dibagi y
|
++
|
Increment
|
x++
|
Sama dengan
x = x+1
|
—
|
Decrement
|
x–
|
Sama dengan
x = x-1
|
2. Operator Bitwise
Adalah operator yang menangani operasi bilangan biner seperti and, or, not dan sebagainya. Operator bitwise ini akan menangani data sesuai dengan tipenya. Misalnya sebuah data bertipe char atau byte maka bilangan yang dihasilkan adalah sebesar 8 bit.Berikut ini beberapa operator bitwise pada bahasa C :
Operator
|
Nama
|
Contoh
|
Dalam
biner (4bit)
|
Hasil
Biner
|
Hasil
Decimal
|
&
|
AND
|
x = 5 &
1
|
0101 &
0001
|
0001
|
1
|
|
|
OR
|
x = 5 | 1
|
0101 | 0001
|
0101
|
5
|
~
|
NOT
|
x = ~ 5
|
~0101
|
1010
|
10
|
^
|
XOR
|
x = 5 ^ 1
|
0101 ^ 0001
|
0100
|
4
|
<<
|
Left shift
|
x = 5
<< 1
|
0101
<< 1
|
1010
|
10
|
>>
|
Right shift
|
x = 5
>> 1
|
0101
>> 1
|
0010
|
2
|
3. Operator Penugasan
Adalah operator yang digunakan untuk memberi nilai pada sebuah variabel. Operator penugasan yang paling dasar adalah sama dengan (=). Dari operator ini dapat dikembangkan beberapa operator penugasan lain seperti +=, -= dan sebagainya.Berikut ini beberapa operator penugasan pada bahasa C :
Operator
|
Penugasan
|
Sama
dengan
|
Deskripsi
|
=
|
x = y
|
x = y
|
variabel x
memperoleh nilai dari variabel y
|
+=
|
x += y
|
x = x + y
|
variabel x
memperoleh nilai dari x + y
|
-=
|
x -= y
|
x = x – y
|
variabel x
memperoleh nilai dari x – y
|
*=
|
x *= y
|
x = x * y
|
variabel x
memperoleh nilai dari x * y
|
/=
|
x /= y
|
x = x / y
|
variabel x
memperoleh nilai dari x / y
|
%=
|
x %= y
|
x = x % y
|
variabel x
memperoleh nilai dari x % y
|
<<=
|
x <<=
y
|
x = x
<< y
|
variabel x
memperoleh nilai dari x << y
|
>>=
|
x >>=
y
|
x = x
>> y
|
variabel x
memperoleh nilai dari x >> y
|
&=
|
x &= y
|
x = x &
y
|
variabel x
memperoleh nilai dari x & y
|
|=
|
x |= y
|
x = x | y
|
variabel x
memperoleh nilai dari x | y
|
^=
|
x ^= y
|
x = x ^ y
|
variabel x
memperoleh nilai dari x ^ y
|
4. Operator Perbandingan
Adalah operator yang digunakan untuk membandingkan dua buah nilai atau variabel. Nilai yang dibandingkan bisa berupa angka maupun string. Hasil dari perbandingan ini berupa nilai boolean, yaitu true (benar) atau false (salah).Berikut ini beberapa operator perbandingan pada bahasa C :
Operator
|
Nama
|
Contoh
|
Hasil
|
==
|
Sama dengan
|
a == b
|
benar jika a
sama dengan b
|
!=
|
Tidak sama
dengan
|
a != b
|
benar jika a
berbeda dengan b
|
>
|
Lebih besar
|
a > b
|
benar jika a
lebih besar dari b
|
<
|
Lebih kecil
|
a < b
|
benar jika a
lebih kecil dari b
|
>=
|
Lebih besar
atau sama dengan
|
a >= b
|
benar jika a
lebih besar atau sama dengan b
|
<=
|
Lebih kecil
atau sama dengan
|
a <= b
|
benar jika a
lebih kecil atau sama dengan b
|
5. Operator Logika
Adalah operator yang digunakan untuk menangani tipe data boolean. Nilai data boolean bisa berupa kondisi benar (true) atau salah (false) dan bisa juga 1 atau 0.Berikut ini beberapa operator logika pada bahasa C :
Operator
|
Nama
|
Contoh
|
Hasil
|
&&
|
And
|
a &&
b
|
benar jika a
and b bernilai benar
|
||
|
Or
|
a || b
|
benar jika
salah satu a atau b bernilai benar
|
!
|
Not
|
!a
|
benar jika a
tidak benar
|
6. Operator Lain
Selain dari beberapa operator diatas, ada beberapa operator lain yang juga sering dipakai terutam pada pemrograman array misalnya operator sizeof dan ppointer (*).
Operator
|
Keterangan
|
Contoh
|
Hasil
|
sizeof()
|
Menghasilkan
ukuran (size) dari variabel.
|
sizeof(a)
|
Menghasilkan
bilangan integer, misal 5
|
&
|
Mengembalikan
alamat (address) dari variabel.
|
&a
|
Menghasilkan
alamat sebenarnya dari variabel
|
*
|
Pointer ke
sebuah variabel.
|
*a
|
Mengarahkan
pointer ke sebuah variabel.
|
? :
|
Operator
kondisi
|
b = (a == 1)
? 20: 30;
|
Jika kondisi
a==1 benar maka nilai b=20 dan jika salah maka nilai b=30
|
INPUT DAN OUTPUT DASAR
a)
FUNGSI KARAKTER
Operasi
Karakter
Fungsi-fungsi pustaka untuk opersai karakter berada pada file judul ctype.h.
a. Menyeleksi Status Karakter
Fungsi-fungsi pustaka atau mako yang dapat digunakan adalah :
Makro-makro ini akan menghasilkan nilai benar (True) jika nilai karakter yang diseleksi termasuk dalam status kelompoknya.
Contoh1 :
#include<stdio.h>
#include<conio.h> //file header untuk fungsi getche()
#include<ctype.h> //file header untuk fungsi isspace(c)
#define lagi 1
main() {
int karakter;
do { karakter = getche(); // menerima input data karakter tanpa enter
if(isspace(karakter)) break; } /*bila yg diinput berupa spasi, backspace, tab atau enter maka keluar dari proses looping*/
while(lagi); /*looping dilakukan selama menerima input*/ }
Contoh2 :
#include<stdio.h>
#include<conio.h>
#include<ctype.h>
main() { int input;
input = getche(); //input tanpa penekanan enter
if(isalpha(input)) printf(“ adalah huruf\n”);
else printf(“ bukan huruf\n”);
}
output :
d adalah huruf
1 bukan huruf
ket : if(isalpha(input)) printf(“adalah huruf\n”); artinya bila input benar berisi karakter huruf maka akan dicetak adalah huruf dan bila tidak akan mencetak bukan huruf.
b. Mengkonversi Nilai Karakter
fungsi :
tolower() : merubah karakter huruf besar menjadi huruf kecil
toupper() : merubah karakter huruf kecil menjadi besar
Contoh :
#include<stdio.h>
#include<conio.h>
#include<ctype.h>
main() { char kata = „A‟,jawab;
do { printf(“%c %c\n”, tolower(kata),toupper(„b‟));
printf(“Mau coba lagi : “);
jawab = getchar(); }
while(toupper(jawab) = = „Y‟ ); }
Ouput :
a B
Mau coba lagi : y
a B
Mau coba lagi : t
Ket : program diatas akan mencetak A menjadi huruf kecil dan B menjadi huruf besar. Perintah while(toupper(jawab) ==‟Y‟) berarti looping akan dilakukan selama jawab = „Y‟ atau „y‟ karena toupper(„y‟) = „Y‟.
Fungsi-fungsi pustaka untuk opersai karakter berada pada file judul ctype.h.
a. Menyeleksi Status Karakter
Fungsi-fungsi pustaka atau mako yang dapat digunakan adalah :
Makro-makro ini akan menghasilkan nilai benar (True) jika nilai karakter yang diseleksi termasuk dalam status kelompoknya.
Contoh1 :
#include<stdio.h>
#include<conio.h> //file header untuk fungsi getche()
#include<ctype.h> //file header untuk fungsi isspace(c)
#define lagi 1
main() {
int karakter;
do { karakter = getche(); // menerima input data karakter tanpa enter
if(isspace(karakter)) break; } /*bila yg diinput berupa spasi, backspace, tab atau enter maka keluar dari proses looping*/
while(lagi); /*looping dilakukan selama menerima input*/ }
Contoh2 :
#include<stdio.h>
#include<conio.h>
#include<ctype.h>
main() { int input;
input = getche(); //input tanpa penekanan enter
if(isalpha(input)) printf(“ adalah huruf\n”);
else printf(“ bukan huruf\n”);
}
output :
d adalah huruf
1 bukan huruf
ket : if(isalpha(input)) printf(“adalah huruf\n”); artinya bila input benar berisi karakter huruf maka akan dicetak adalah huruf dan bila tidak akan mencetak bukan huruf.
b. Mengkonversi Nilai Karakter
fungsi :
tolower() : merubah karakter huruf besar menjadi huruf kecil
toupper() : merubah karakter huruf kecil menjadi besar
Contoh :
#include<stdio.h>
#include<conio.h>
#include<ctype.h>
main() { char kata = „A‟,jawab;
do { printf(“%c %c\n”, tolower(kata),toupper(„b‟));
printf(“Mau coba lagi : “);
jawab = getchar(); }
while(toupper(jawab) = = „Y‟ ); }
Ouput :
a B
Mau coba lagi : y
a B
Mau coba lagi : t
Ket : program diatas akan mencetak A menjadi huruf kecil dan B menjadi huruf besar. Perintah while(toupper(jawab) ==‟Y‟) berarti looping akan dilakukan selama jawab = „Y‟ atau „y‟ karena toupper(„y‟) = „Y‟.
b)
FUNGSI PRINT DAN SCANF
Printf merupakan sebuah fungsi dalam
file header <stdio. h>. Printf digunakan untuk membuat sebuah output
berupa tampilan. contoh:
#include <stdio.h>
void main()
{
printf (” ILC DONK “) ;
}
kata yang akan di tampilkan di ketik
di antara tanda (” “). dan dalam setiap statement harus di akhiri dengan tanda”
; “.
selanjutnya kita bahas tentang
scanf.
scanf merupakan sebuah fungsi dalam
file header <stdio.h> juga yang berfungsi untuk menerima inputan dari
user. Untuk belajar tentang scanf kita pelajari dulu tentang variabel. Variabel
di ibaratkan sebuah wadah untuk menampung sebuah nilai maupun karakter dari
inputan user ataupun sudah di tentukan dari awal. Ada banyak macam tipe
variabel
- int -> untuk menampung nilai
- char -> untuk menampung karakter
- dll
untuk inisialisasi awal sebuah
variabel dapat di ketik <tipe variabel><spasi><nama
variabel>, contoh char nama;
ini berarti kita membuat variabel
nama bertipe karakter
simak contoh berikut ini
#include <stdio.h>
void main()
{
char nama[10];
{
char nama[10];
printf(“Masukkan nama:”);
scanf(“%s”,&nama);
printf(“\n\n%s\n”,&nama);
}
scanf(“%s”,&nama);
printf(“\n\n%s\n”,&nama);
}
c)
FUNGSI STRING
Operasi String
Suatu string merupakan array dari karakter. Nilai suatu string ditulis dengan tanda petik dua. Suatu nilai string disimpan di memory dengan diakhiri oleh nilai „\0‟ (null). “ABC” disimpan menjadi A B C „\0‟
Inisialisasi
String : char kota[ ] = {„C‟,‟o‟,‟r‟,‟v‟,‟a‟,‟l‟,‟l‟,‟i‟,‟s‟,‟\0‟};
char kota[10] = “Corvallis” ;
char kota[ ] = “Corvallis” ;
Konstanta string, sebagaimana halnya nama array, diperlakukan oleh kompiler sebagai sebuah pointer. Maka pernyataan berikut sama dengan inisialisasi di atas.
char *kota = “CORVALLIS”;
perintah : printf(“%s, %c%c”, kota, kota[1],kota[2]); Output : CORVALIS, OR
%s kode format untuk kota berarti mencetak CORVALLIS. %c, kota[1] berarti mencetak elemen array ke-1 dari kota yaitu „O‟, %c,kota[2] berarti mencetak elemen array ke-2 dari kota yaitu „R‟.
Seperti halnya Array, String bila tidak diberi nilai awal maka ukuran karakter harus ditulis, Misal : char Nama[20];
Atau boleh ditulis sebagai pointer :
char *Nama ;
Fungsi2 standar string terdapat pada file judul string.h
1. Menyalin string
Fungsi : strcpy()
Bentuk : srtcpy(string1,string2). Nilai string2 akan dicopy ke string1.
Contoh : strcpy(kota, “satu”) maka string satu akan dicopy ke variable kota.
2. Menghitung panjang string
Fungsi : strlen()
Contoh : strlen(“Corvallis”) maka akan dihasilkan nilai 9
3. menggabungkan string
fungsi : strcat(string1,string2). Nilai string1 akan digabung dengan string2 dan disimpan didalam string1.
Contoh :
char kota[]=”satu”;
strcat(kota, “dua”) maka kota[ ] = “satudua”
4. Mencari Nilai karakter di string
Fungsi : strchr()
Contoh :
char String[ ] =”Abcde”; char *hasil ;
Hasil = strch(String, „B‟); printf(“%s”, hasil);
Maka Hasil akan bernilai “Bcde”
5. Membandingkan dua nilai string
Fungsi : strcmp()
Membandingkan dua nilai string akan menghasilkan nilai integer berupa :
- > 0 bila sring pertama lebih kecil daripada string kedua
- 0 bila string pertama = string kedua
- < 0 bila string pertama lebih besar dari string kedua
Contoh program :
#include <stdio.h>
#include “string.h”
int main( ) {
char kata1[ ] = “Ibu Kota”, *kata2 = “ Jakarta”, data1[ ] ={„A‟,‟B‟,‟c‟,‟d‟,‟\0‟};
char data2[ ] = “ABCD”,*baru ; int hasil;
printf(“panjang string kata1 : %d \n”,strlen(kata1); //menghitung panjang “Ibu Kota”
strcat(kata1,kata2); //mengabung kata1&kata2 disimpan di kata1
printf(“nilai string kata1 setelah operasi : %s \n”,kata1);
strcpy(kata2,data1); //mencopy string data1 disimpan di kata2
printf(“nilai string kata2 setelah operasi : %s \n”,kata2);
hasil = strcmp(data1,data2); //membandingkan data1 dan data2
if (hasil = = 0) printf(“Data1 sama dengan data2”)
else if(hasil< 0) printf(“Data1 lebih kecil dari data2”);
else printf(“Data1 lebih besar dari data2”);
baru = strchr(data2,’C’); //mencari karakter‟C‟ pada data2, hasil disimpan di baru
printf(“\nHasil mencari karakter C : %s”, baru);
return 0; //nilai balik ke fungsi main
}
Output :
panjang string kata1 : 8
Nilai string kata1 setelah operasi : Ibu Kota Jakarta
Nilai string kata2 setelah operasi : ABcd
Data1 lebih besar dari data2
Hasil mencari karakter C : CD
Nilai yang tersimpan pada tiap variabl setelah operasi :
kata1= “Ibu Kota Jakarta” karena menyimpan hasil operasi strcat(kata1,kata2).
kata2 = “Abcd” karena menyimpan hasil opersi strcpy(kata2,data1)
data1 = “Abcd”
data2 = “ABCD”
hasil = lebih besar dari nol karena karakter „c‟ lebih besar dari „C‟
baru = “CD”
Suatu string merupakan array dari karakter. Nilai suatu string ditulis dengan tanda petik dua. Suatu nilai string disimpan di memory dengan diakhiri oleh nilai „\0‟ (null). “ABC” disimpan menjadi A B C „\0‟
Inisialisasi
String : char kota[ ] = {„C‟,‟o‟,‟r‟,‟v‟,‟a‟,‟l‟,‟l‟,‟i‟,‟s‟,‟\0‟};
char kota[10] = “Corvallis” ;
char kota[ ] = “Corvallis” ;
Konstanta string, sebagaimana halnya nama array, diperlakukan oleh kompiler sebagai sebuah pointer. Maka pernyataan berikut sama dengan inisialisasi di atas.
char *kota = “CORVALLIS”;
perintah : printf(“%s, %c%c”, kota, kota[1],kota[2]); Output : CORVALIS, OR
%s kode format untuk kota berarti mencetak CORVALLIS. %c, kota[1] berarti mencetak elemen array ke-1 dari kota yaitu „O‟, %c,kota[2] berarti mencetak elemen array ke-2 dari kota yaitu „R‟.
Seperti halnya Array, String bila tidak diberi nilai awal maka ukuran karakter harus ditulis, Misal : char Nama[20];
Atau boleh ditulis sebagai pointer :
char *Nama ;
Fungsi2 standar string terdapat pada file judul string.h
1. Menyalin string
Fungsi : strcpy()
Bentuk : srtcpy(string1,string2). Nilai string2 akan dicopy ke string1.
Contoh : strcpy(kota, “satu”) maka string satu akan dicopy ke variable kota.
2. Menghitung panjang string
Fungsi : strlen()
Contoh : strlen(“Corvallis”) maka akan dihasilkan nilai 9
3. menggabungkan string
fungsi : strcat(string1,string2). Nilai string1 akan digabung dengan string2 dan disimpan didalam string1.
Contoh :
char kota[]=”satu”;
strcat(kota, “dua”) maka kota[ ] = “satudua”
4. Mencari Nilai karakter di string
Fungsi : strchr()
Contoh :
char String[ ] =”Abcde”; char *hasil ;
Hasil = strch(String, „B‟); printf(“%s”, hasil);
Maka Hasil akan bernilai “Bcde”
5. Membandingkan dua nilai string
Fungsi : strcmp()
Membandingkan dua nilai string akan menghasilkan nilai integer berupa :
- > 0 bila sring pertama lebih kecil daripada string kedua
- 0 bila string pertama = string kedua
- < 0 bila string pertama lebih besar dari string kedua
Contoh program :
#include <stdio.h>
#include “string.h”
int main( ) {
char kata1[ ] = “Ibu Kota”, *kata2 = “ Jakarta”, data1[ ] ={„A‟,‟B‟,‟c‟,‟d‟,‟\0‟};
char data2[ ] = “ABCD”,*baru ; int hasil;
printf(“panjang string kata1 : %d \n”,strlen(kata1); //menghitung panjang “Ibu Kota”
strcat(kata1,kata2); //mengabung kata1&kata2 disimpan di kata1
printf(“nilai string kata1 setelah operasi : %s \n”,kata1);
strcpy(kata2,data1); //mencopy string data1 disimpan di kata2
printf(“nilai string kata2 setelah operasi : %s \n”,kata2);
hasil = strcmp(data1,data2); //membandingkan data1 dan data2
if (hasil = = 0) printf(“Data1 sama dengan data2”)
else if(hasil< 0) printf(“Data1 lebih kecil dari data2”);
else printf(“Data1 lebih besar dari data2”);
baru = strchr(data2,’C’); //mencari karakter‟C‟ pada data2, hasil disimpan di baru
printf(“\nHasil mencari karakter C : %s”, baru);
return 0; //nilai balik ke fungsi main
}
Output :
panjang string kata1 : 8
Nilai string kata1 setelah operasi : Ibu Kota Jakarta
Nilai string kata2 setelah operasi : ABcd
Data1 lebih besar dari data2
Hasil mencari karakter C : CD
Nilai yang tersimpan pada tiap variabl setelah operasi :
kata1= “Ibu Kota Jakarta” karena menyimpan hasil operasi strcat(kata1,kata2).
kata2 = “Abcd” karena menyimpan hasil opersi strcpy(kata2,data1)
data1 = “Abcd”
data2 = “ABCD”
hasil = lebih besar dari nol karena karakter „c‟ lebih besar dari „C‟
baru = “CD”
d)
COUNTINUATION CHARACTER
Continuation character
Baris
panjang kode tidak nyaman jika aplikasi editor skrip Anda tidak membungkusnya.
Dalam lingkungan seperti itu, jika kode Anda berisi garis panjang dan Anda
ingin dapat membacanya tanpa menggulir secara horizontal, Anda perlu cara untuk
memecah garis panjang. Karena sebuah baris adalah unit sintaksis yang bermakna,
Anda tidak dapat melakukan ini hanya dengan memasukkan karakter kembali.
Sebaliknya, Anda juga harus memasukkan karakter kelanjutan.
TIP
Masalah
yang diselesaikan karakter lanjutan tidak lagi menjadi masalah besar, karena
aplikasi editor skrip saat ini memang membungkus garis panjang.
Karakter
kelanjutan muncul sebagai tanda "tidak logis"; itu adalah codepoint
MacRoman 194, Unicode (dan WinLatin1 dan ISOLatin1) codepoint 172. Karakter ini
biasanya diketik pada Macintosh sebagai Option-L; tetapi sebagai kenyamanan,
dalam aplikasi editor skrip, mengetik Option-Return memasukkan karakter
logical-not dan karakter return, dan merupakan cara biasa untuk melanjutkan
sebuah baris. Sebagai contoh:
atur
ke ¬
1
Ini
adalah kesalahan waktu kompilasi untuk apa pun untuk mengikuti karakter
lanjutan pada baris yang sama selain spasi putih.
Ini
adalah kesalahan kompilasi-waktu untuk baris berikut karakter kelanjutan
menjadi kosong, kecuali apa yang mendahului karakter kelanjutan adalah perintah
yang lengkap, seperti dalam contoh yang sangat konyol ini:
atur
ke 1 ¬
atur
b ke 2
Karakter
lanjutan dalam string literal ditafsirkan sebagai karakter logis-bukan literal.
Untuk memecah string literal panjang menjadi beberapa baris kode untuk
keterbacaan tanpa ...
SUMBER
http://www.materidosen.com/2017/02/pengertian-jenis-dan-contoh-identifier.html https://b3rbagilmu.blogspot.com/2016/06/keyword-dalam-bahasa-c.html (https://www.duniailkom.com/tutorial-belajar-c-jenis-jenis-tipe-data-dalam-bahasa-c/ https://www.petanikode.com/c-variabel/ http://haqcoding.blogspot.com/2017/07/pengertian-deklarasi-di-pemrograman.html
Komentar
Posting Komentar